Java és a szemantikus web
A Web 2.0 után manapság egyre divatosabb fogalom a szemantikus web, melynek célja pont az egyre növekvő, ember számára feldolgozhatatlan mennyiségű információ hasznosítása. Jelenleg, ha egy kérdésre keressük a választ, keresőket használunk, és próbálunk egy olyan keresési kifejezést megadni, melyre eredményül hozott oldalak a témához minél jobban illeszkedjenek. A találatok sorrendjénél a legelterjedtebb kereső, a Google a weben legjobban mérhető tetszésnyilvánításokat veszi figyelembe, méghozzá a linkeléseket.
A szemantikus web célja, hogy a különböző számítógépes rendszerek az egzakt kérdéseinkre a lehető legegzaktabb választ adják, azaz ezek a rendszerek ne csak feldolgozzák, indexeljék és mintát illesszenek a weboldalakra, hanem értelmezzék is azokat, mi több, következtetéseket is tudjanak levonni. Ezt úgy gondolják megvalósítani, hogy a különböző weboldalakhoz, tágabb értelemben információforrásokhoz számítógép által is feldolgozható metaadatokat rendelnek, melyek kellően kötöttek ahhoz, hogy következtetéseket lehessen belőlük levonni.
Erre ki is alakítottak egy RDF (Recource Description Framework – Erőforrás-Leíró Keretrendszer) nevű adatmodellt, mely a W3C által karbantartott szabvány, és ennek segítségével metaadatokat lehet szabványos módon megadni. Egy RDF egyszerű kijelentő mondatok gyűjteménye (tripletek), melyek egy alanyt (subject), egy állítmányt (predicate) és egy tárgyat (object) tartalmaznak. Mind az alany, mind a tárgy egy gráfban jelenik meg csomópontként, és az állítás pedig egy irányított kapcsolatként, így jön létre egy irányított gráf. Az alany egy erőforrás, melyet egy URI-val lehet egyértelműen azonosítani. Léteznek ún. üres erőforrások is. Az állítmányok szintén erőforrások. A tárgy lehet erőforrás, vagy egy literál is (ez utóbbi önmagát magyarázza). A literál lehet típus nélküli, vagy típusos, mint pl. szöveges, szám vagy dátum. Ezen adatmodellel ábrázolt adatokat különböző formátumokban lehet tárolni, szállítani (un. szerializálás), ezek közül a leggyakoribb az XML. Az erre szolgáló XML formátumot is szokták RDF-nek nevezni, ne mi ne keverjük össze a metaadat-modellt, valamint annak tárolási módját.
Az OWL (Web Ontology Language) ennél magasabb szinten helyezkedik el, és feladata ontológiák leírása. Az ontológiák egy tudásterület alapfogalmainak, valamint ezek összefüggéseinek géppel értelmezhető definícióit tartalmazzák. Az ontológiákat olyan emberek, adatbázisok és alkalmazások használják, akiknek/amelyeknek egy bizonyos tudásterületen együtt kell működniük (ilyen lehet egy szűkebb tudományos, gazdasági vagy kulturális terület). A nyelvnek is három változata létezik, melyek egyre nagyobb kifejezőerővel bírnak. Ebből első az OWL Lite egyszerűbb ontológiák megfogalmazásához, a második az OWL DL (Description Logics), mely már többet nyújt, viszont az automatikus számíthatóság még garantált, és a harmadik az OWL Full, mely a teljes kifejezőerőt biztosítják, de cserébe le kell mondani az automatikus számíthatóság garanciájáról. Az OWL Full az RDF kiterjesztése, míg az OWL korlátozottabb szintjei az RDF korlátozott nézetének kiterjesztései.
Az OWL alapfogalmai az egyed (instance), a tulajdonság (property) és a class (osztály). Az egyedek alkotják a fogalmakat, a köztük lévő kapcsolatokat a tulajdonságok. Az osztály az objektumorientált szemlélethez hasonlóan egy magasabb absztrakciós szint, és egy osztályba sorolja az azonos tulajdonsággal rendelkező egyedeket.
Az RDF és OWL bemutatására, valamint a Java fogalmak rendszerezésére kialakítottam egy egyszerű ontológiát. Középpontban áll a probléma (Problem), melyet valamilyen módszertan, technika, stb. (Method) old meg. Ezt bizonyos gyártók, szervezetek (Organisation) által készített, gyártott, fejlesztett termékei (Product) használják fel a probléma megoldására valamilyen szabványt (Specification) implementálva. Az osztályok között tartalmazási és együttműködési kapcsolat is fennállhat.
[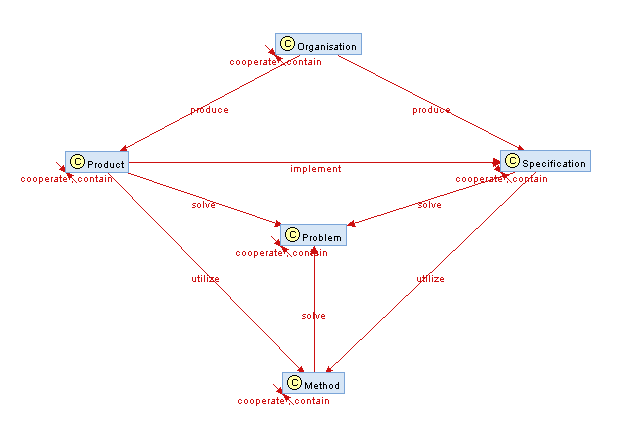
Nézzünk erre egy egyszerű példát. Probléma a perzisztencia, azaz az üzleti objektumainkat szeretnénk perzisztens tárba elmenteni. Erre egy remek módszer az objektumorientált világban az ORM (object-relational-mapping), mely az objektumokat relációs adatbázisba képzi le. Erre már egy szabványt, a JPA szabványt meg is alkották, és erre több implementációt is kiadtak, mint a RedHat JBoss által jegyzett Hibernate-et, vagy az Oracle által jegyzett Toplink-et.
Látható, hogy így egy viszonylag nagy ontológiát lehet felépíteni, mely a Java-val kapcsolatos fogalmak nagy részét ábrázolni tudja és ezekből következtetéseket is tud levonni. Könnyen megfogalmazhatóak összetett kérdések, melyre a gép automatikusan választ tud adni. Pl. melyek azok a termékek, melyek a perzisztenciát oldják meg, lehetőleg támogatják a JPA specifikációt, és nem Oracle termékek.
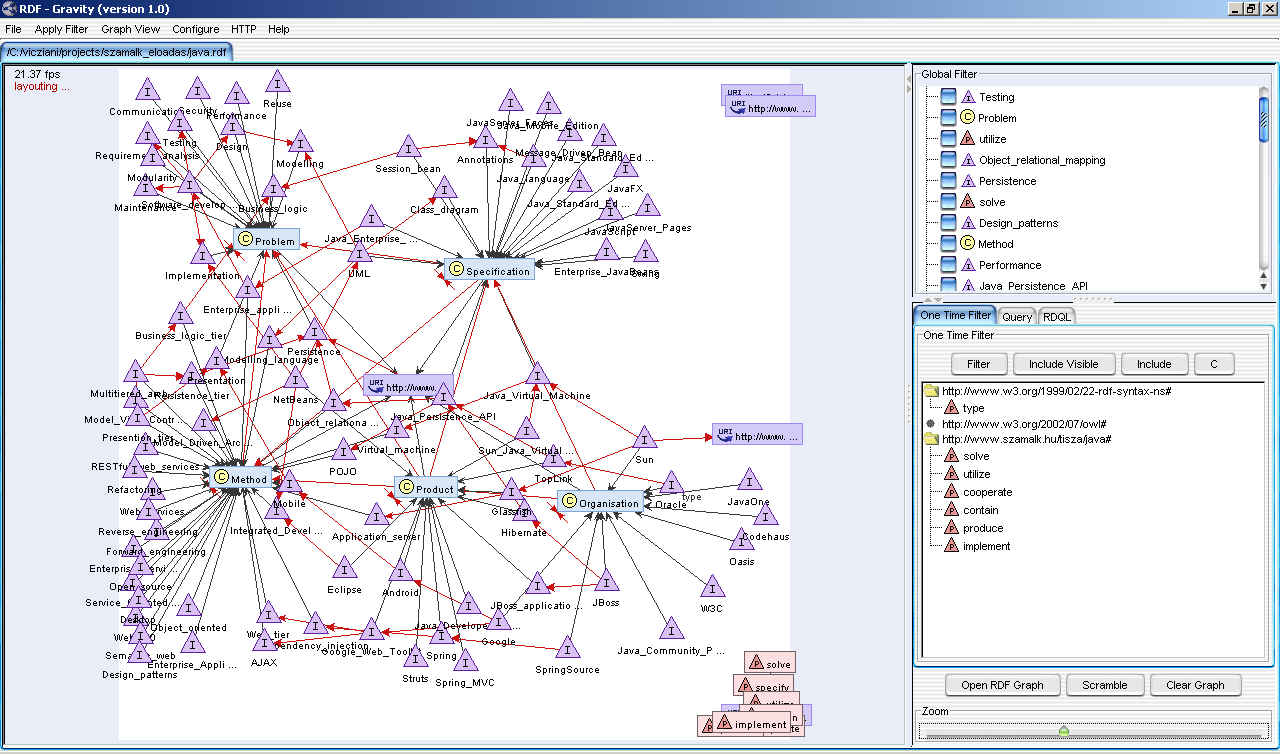
Az RDF/OWL formátumok szerkesztéséhez már rengeteg eszköz megjelent, ebből egy lehet pl. az Altova SemanticWorks, mely meglehetősen bugos, valamint a pilótavizsgás, de nagyon komoly, Java alapú Protégé nevezetű ingyenes, nyílt forráskódú eszköz. Megjelenítéshez az RDF – Gravity eszközt használtam.
A fogalmak összegyűjtésére már elindult egy kezdeményezés Magyarországon a http://jhacks.anzix.net/space/topics címen, de ez egy egyszerű wiki, ami képes a fogalmak leírására, és a köztük lévő kapcsolatok definiálására. Azonban a számítógéppel való feldolgozáshoz szükség van arra, hogy az oldalakhoz és akár a linkekhez is metaadatokat helyezzünk el. Az egyik legelterjedtebb wiki rendszerhez, a MediaWiki-hez már van olyan kiegészítő, melyekhez ilyent meg tudunk adni Semantic MediaWiki néven (http://semantic-mediawiki.org/wiki/Semantic_MediaWiki).