SonarQube
Bár a SonarQube (korábban egyszerűen csak Sonar) a Java fejlesztés alap eszköztárába tartozik, mégsem írtam még róla, így ezzel a poszttal ezt szeretném bepótolni.
A SonarQube egy olyan komplex szoftverrendszer, mely azt biztosítja, hogy folyamatosan nyomon tudjuk követni a kódunk minőségét (ezt Continuous Code Quality-nek nevezi). A projektünkre statikus kódelemzőket lehet futtatni, melyek elemzik a forráskódot, és annak feltérképezésével próbálnak hibás részeket keresni. (Ezek általában rossz programozási gyakorlatok, az idők során kialakult programozási konvencióknak ellentmondó kódrészletek, vagy tipikus - nem olyan gyakorlott fejlesztők által elkövetett típushibák). A SonarQube-ot először Java nyelvre fejlesztették, de már több, mint húsz programozási nyelvet támogat (, akár egy projekten belül, pl. Java backend, és JavaScript frontend). A SonarQube ezen elemzések eredményét képes hisztorikusan tárolni, így nyomon követhető, hogy idővel hogyan alakul a kódunk minősége. Ezen kívül képes a tesztlefedettséget is tárolni, hogy az automatikus tesztek futása során mely utasítások lettek végrehajva, és mely osztályokra, metódusokra, végrehajtási ágakra nincs tesztünk. Ezeket az információkat nem csak tárolni tudja, hanem egy intuitív felületen képes ezeket meg is jeleníteni. A SonarQube tetszőleges számú projekt adatait képes tárolni és megjeleníteni. Nyílt forráskódú, de licensz is vásárolható, mellyel támogatást kapunk, illetve más nyelvhez is elemzőket.
Nézzük meg, hogy milyen komponensekből áll a SonarQube, hogyan lehet telepíteni, és hogyan elemezhetünk ki vele egy projektet, és hogyan integrálható a fejlesztőeszközünkkel (IDEA, Eclipse és NetBeans).
Felépítése
Először nézzük meg a SonarQube architektúráját. Az adatokat egy relációs adatbázisban tárolja (támogatott a PostgreSQL, MySQL, Oracle és Microsoft SQL Server is), ezzel nekünk kevés dolgunk van. A következő komponens a SonarQube Server, mely fogadja, feldolgozza és tárolja az adatbázisban az elemzések eredményeit. Ez biztosítja a webes felületet a felhasználóknak, illetve rendelkezik egy keresőmotorral is. A Server tovább bővíthető nyílt forráskódú, kereskedelmi, de akár magunk által készített pluginekkel is.
A következő fontos komponensek a SonarQube Scanner elemzők, melyek képesek elemezni a forráskódot, és továbbítani a Servernek.
Ezek alapján a fejlesztési folyamat során a fejlesztő publikálja az új forráskódot a verziókövető rendszerbe, melyet a Continuous Integration szerver folyamatosan figyel, és lefuttatja a megfelelő Scannert. A Scanner az adatokat továbbítja a Server felé. (Ez régen úgy történt, hogy közvetlenül az adatbázisba írt, szerencsére azóta az megváltozott, és a Scanner az eredményeket REST API-n küldi fel a Server számára.) A Server ezek után aszinkron módon elkezdi feldolgozni az adatokat, letárolni az adatbázisban, és amint végzett ezzel, az eredmény elérhető a webes felületen, és kereshetővé is válik. (Sajnos a SonarQube jelenleg nem clusterezhető, ezért érdemes külön szerverre tenni a adatbázist és a Servert, valamint külön szervereken, külön CI server node-okon futtatni a Scannereket.)
A Java Scannerrel kapcsolatban érdemes megemlíteni azt, hogy korábban a SonarQube már létező eszközöket (PMD, CheckStyle, FindBugs) használt a statikus kódelemzésre, de mivel ezekre kevés ráhatásuk volt, nem fejlődtek olyan mértékben, és kevésbé voltak illeszthetőek a SonarQube ökoszisztémába, ezért úgy döntöttek, hogy újraírják az azokban szereplő szabályok egy általuk hasznosnak ítélt részét a SonarQube Java Analyzerben.
A FindBugs utoljára 2015. márciusában frissült, akkor jött ki a 3.0.1 verzió, mely 424 szabályt tartalmaz. A SonarQube jelenlegi legfrissebb 6.3 verziója 2017. márciusában jött ki, és 397 Java szabályt tartalmaz.
Használatba vétel
A SonarQube viszonylag gyorsan kipróbálható. Töltsük le a legfrissebb verziót, amelyet
csomagoljunk ki. Ekkor 64 bites Linux esetén elegendő a bin/linux-x86-64/sonar.sh console parancsot kiadnunk, és el is indul. Külön
adatbázis telepítése sem szükséges, hiszen ilyenkor beépített adatbáziskezelőt használ. Így ne használjuk éles környezetben, erre a felület
is figyelmeztet minket. Indítás után ez elérhető a http://localhost:9000 címen, az alapértelmezett felhasználónév és jelszó admin/admin.
Amennyiben Maven projektünk van, az elemzés konfiguráció nélkül azonnal futtatható a következő parancs kiadásával:
mvn clean verify sonar:sonar
Ekkor alapértelmezetten a localhoston futó Sonar Serverhez kapcsolódik. Természetesen ezt meg lehet változtatni. Valamint érdemes a Maven Plugin verziószámát fixálni. Ezek a konfigurációs lehetőségek megtalálhatóak a Maven Plugin dokumentációjában. Az elemzés is külön konfigurálható, a paraméterek dokumentációja megtalálhatóak a Analysis Parameters dokumentációban.
Ekkor azonban még nincs teszt lefedettség, ehhez egy külön eszközt kell használnunk, pl. a JaCoCo-t, vagy a Coberturat.
Amennyiben JaCoCo-t választjuk, elegendő a következő parancsot kiadni:
mvn clean org.jacoco:jacoco-maven-plugin:prepare-agent verify sonar:sonar -Dmaven.test.failure.ignore=true
Ez valójában beállítja, hogy a Surefire futtatásakor a JaCoCo legyen Java Agent. Ez úgy módosítja a Java alkalmazás futását, hogy a különböző
utasítások lefutásának tényét egy riport fájlba írja (target/jacoco.exec fájl). Ezt a riportot dolgozza fel a Scanner és küldi fel a Servernek.
Fogalmak
A SonarQube elég sok fogalmat definiál. Alapvetően rengeteg szabályt (rule) tartalmaz a különböző programozási nyelvekre. Nézzünk meg néhány szabályt említés jelleggel Java esetén:
- squid:S2975 - “clone” should not be overridden - Hatékony Java könyv alapján nem érdemes a clone metódust felülírni
- squid:S2095 - Resources should be closed - Erőforrásokat le kell zárni
- squid:SwitchLastCaseIsDefaultChec - “switch” statements should end with “default” clauses - switch utasításban legyen default ág
- squid:S2387 - Child class fields should not shadow parent class fields - gyerek osztályban az attribútum ne fedje el az ősben definiált attribútumot
Mindegyik szabályhoz nagyon részletes leírás is tartozik, példakódokkal, érdemes ezeket is olvasgatni. Ezen kívül minden szabálynak van egy azonosítója is (squid), később megnézzük, hogyan lehet rá hivatkozni. Van egy típusa is. A bug hibát jelöl. A vulnerability biztonsági sebezhetőséget, pl. kódba égetett jelszó. A code smell pedig gyanús kódot (lásd Refactoring könyv). Ezen kívül a szabályhoz súlyosságot is lehet rendelni (Blocker, Critical, Major, Minor, Info). Ezen kívül különböző címkékkel lehet ellátni.
A következő fogalom a Quality Profile. Egy Quality Profile-on belül meg lehet adni, hogy mely szabályokat vegye figyelembe az elemzés során, és felül lehet bírálni a szabály súlyosságát. Több ilyen Quality Profile adható meg, és minden projekthez pontosan egy Quality Profile rendelhető. Így különböző szabálygyűjteményeket definiálhatunk, és rendelhetünk különböző projektekhez. Hiszen lehet, hogy más csapatok más szabályokkal dolgoznak, és lehet, hogy egy több éve futó projektet másképp kell elemezni, mint egy most indult zöldmezős projektet.
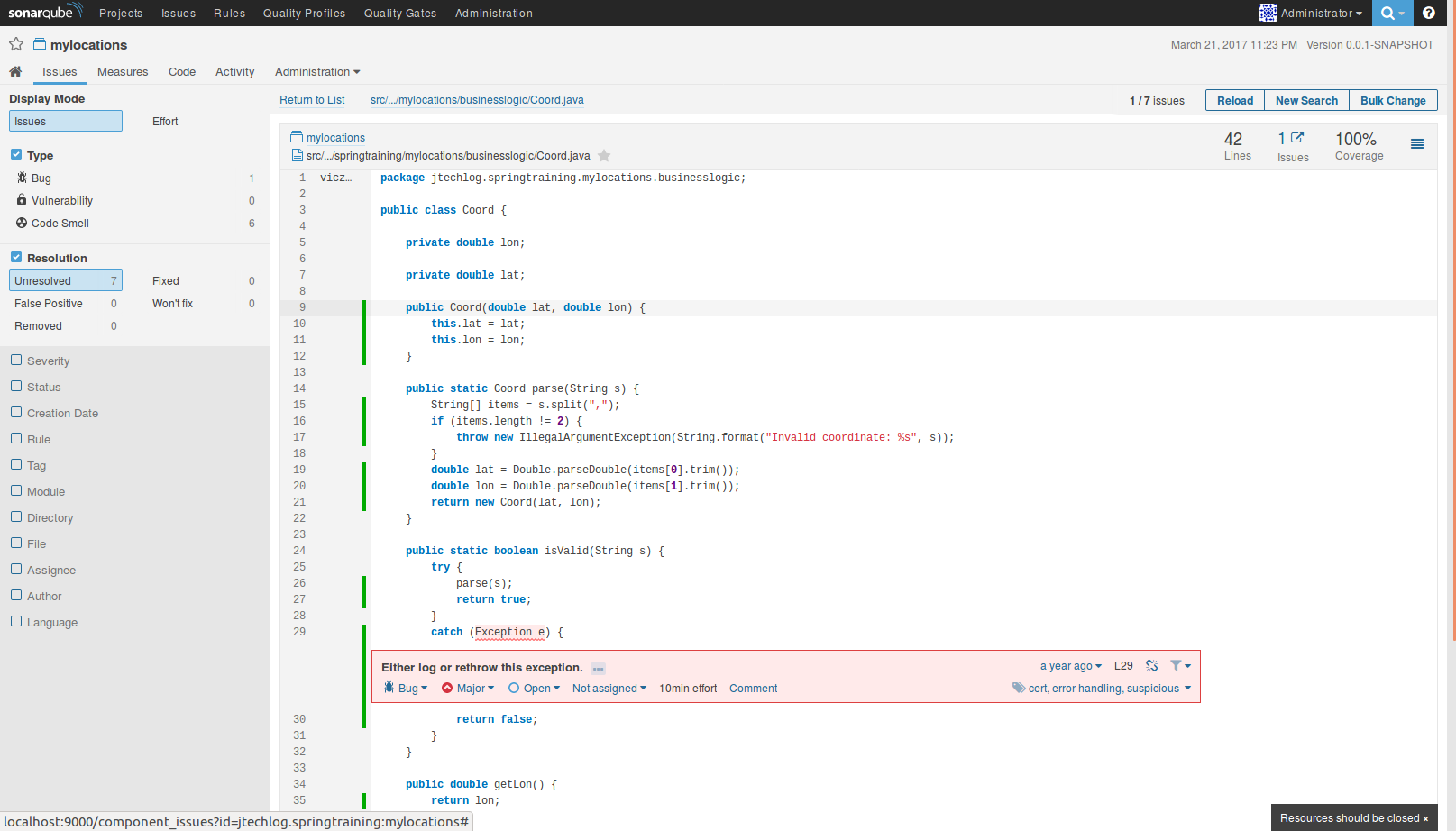
Az Issues az adott projekten felmerülő szabálysértések. Egy adott issue-t meg lehet nézni a forráskódban is. Kiírja, hogy mely fejlesztő írta azt a kódrészletet és mikor, melyben az issue szerepel (ezt az információt a verziókövető rendszerből nyeri). De lehet módosítani a típusát, súlyosságát, címkéket lehet hozzáadni vagy elvenni. Hozzá lehet rendelni egy felhasználóhoz, hogy ki javítsa ki, sőt megjegyzést is lehet írni. Valamint nyílt (open) státuszból más státuszba is lehet tenni (pl. fixed, ha javítva lett, vagy false positive, ha téves a riasztás).
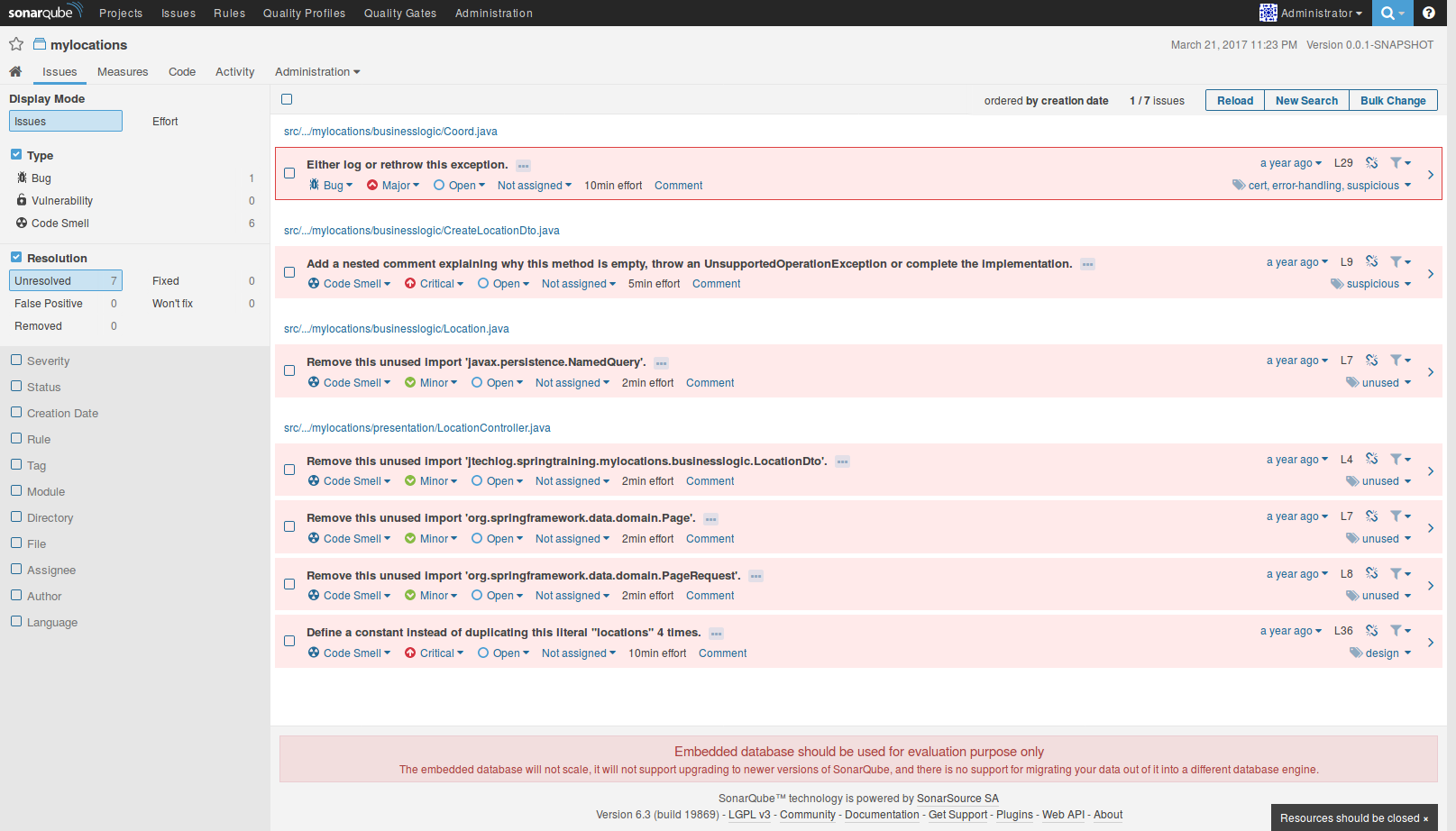
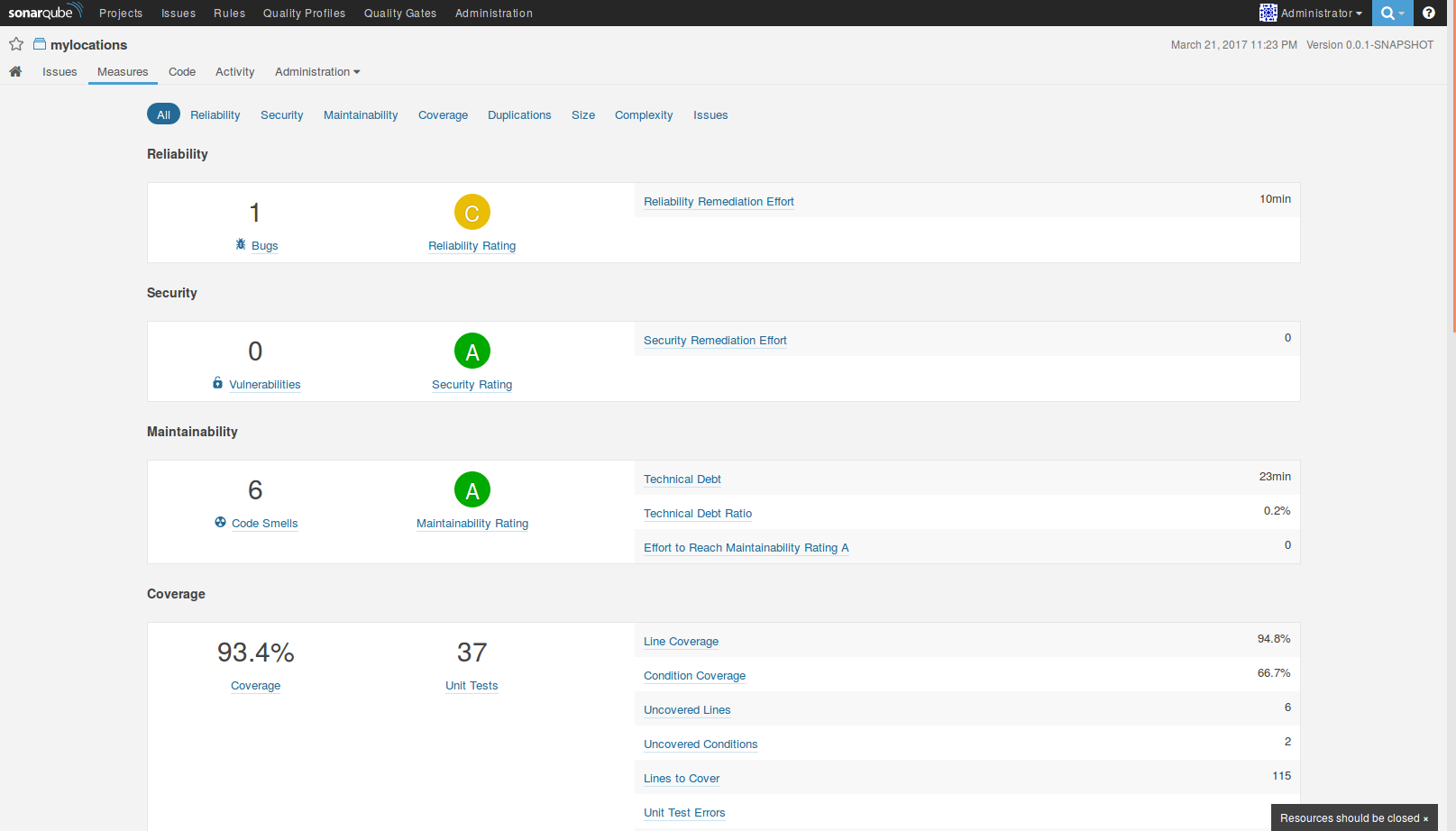
A Measures különböző mérőszámokat rendel a projekthez, melyeket tovább lehet utána bontani akár osztály szintre is. Ilyen pl. a különböző típusú issue-k száma, a kód lefedettséggel kapcsolatos mérőszámok (lefedettség, tesztesetek, száma, futás hossza, stb.), duplikált kód (copy-paste), a kódbázis mérete (osztályok, metódusok, sorok száma), komplexitás és a különböző státuszú issue-k száma. A projektet hibák száma (Reliability/Bugs), biztonsági hibák száma (Security/Vulnerabilities) és gyanús kód (Maintainability/Code Smells) mennyisége alapján különböző osztályokba sorolja (rating). Ez A - E értékeket vehet fel, ahol az A legjobb, és E a legrosszabb. Próbálja mérni a Technical Debtet is, azáltal, hogy megbecsüli, hogy egy Issue kijavítása mennyi időbe telik. A Technical Debt valójában az a munkamennyiség, mely ahhoz kell, hogy kijavítsuk a határidő nyomás és egyéb körülmények miatti (eufemisztikusan) nem a legmegfelelőbb megoldásokat. Ezektől még lehet, hogy az alkalmazás funkcionálisan megfelelő, azonban a kód minősége hagyhat kívánnivalót maga után, tipikusan nehezebben érthető, módosítható, továbbfejleszthető.
Következő fogalom a Quality Gate, mely olyan feltételgyűjtemény, melyet ha nem teljesít a projekt, nem engedjük kiadni. Több Quality Gate-et is definiálhatunk, és ezeket projektekhez rendelhetjük. Olyanokat adhatunk meg, hogy mekkora legyen a megengedhető issue-k száma, a minimális tesztlefedettség, a duplikált kód maximális mérete, a maximális komplexitás, stb. Valójában az összes mérőszámra lehet határértékeket beállítani. Nem csak a régi kódra, hanem az újonnan bekerült kódra vonatkozóan is.
Quality Gate használata
A Quality Gate esetén eszünkbe juthat, hogy arra használjuk, hogy buktassa a Continuous Integration rendszeren a buildet. Ez azonban több szempontból sem jó ötlet. Egyrészt a feldolgozás aszinkron módon zajlik, és függ a Sonar Server leterheltségétől. Amiatt várakoztatni a build folyamat, hogy lefusson az elemzés, nem jó gyakorlat, és implementálni sem egyszerű, hiszen pollingolni kell a szervert, hogy lefutott-e már (az URL-t, melyen ellenőrizhető - JSON formátumban - hogy lefutott-e, a Sonar Maven Plugin kiírja a konzolra). Valamint könnyen lehet, hogy minél gyorsabban szeretnénk az új kódot megosztani akár a többi fejlesztővel, akár a tesztelőkkel, anélkül, hogy az minőségben a megfelelő lenne. Ezért a SonarQube fejlesztői szerint se törje meg a buildet a Quality Gate, hanem inkább használjunk erre értesítéseket, esetleg egy dashboardot, melyet folyamatosan figyelemmel követünk, és akkor foglalkozunk vele, ha erre van lehetőség (pl. refaktoring keretében, ahol a funkcionalitást nem módosítjuk, csupán a kódot struktúráljuk át - ebben segít nekünk a magas tesztlefedettség).
SonarLint
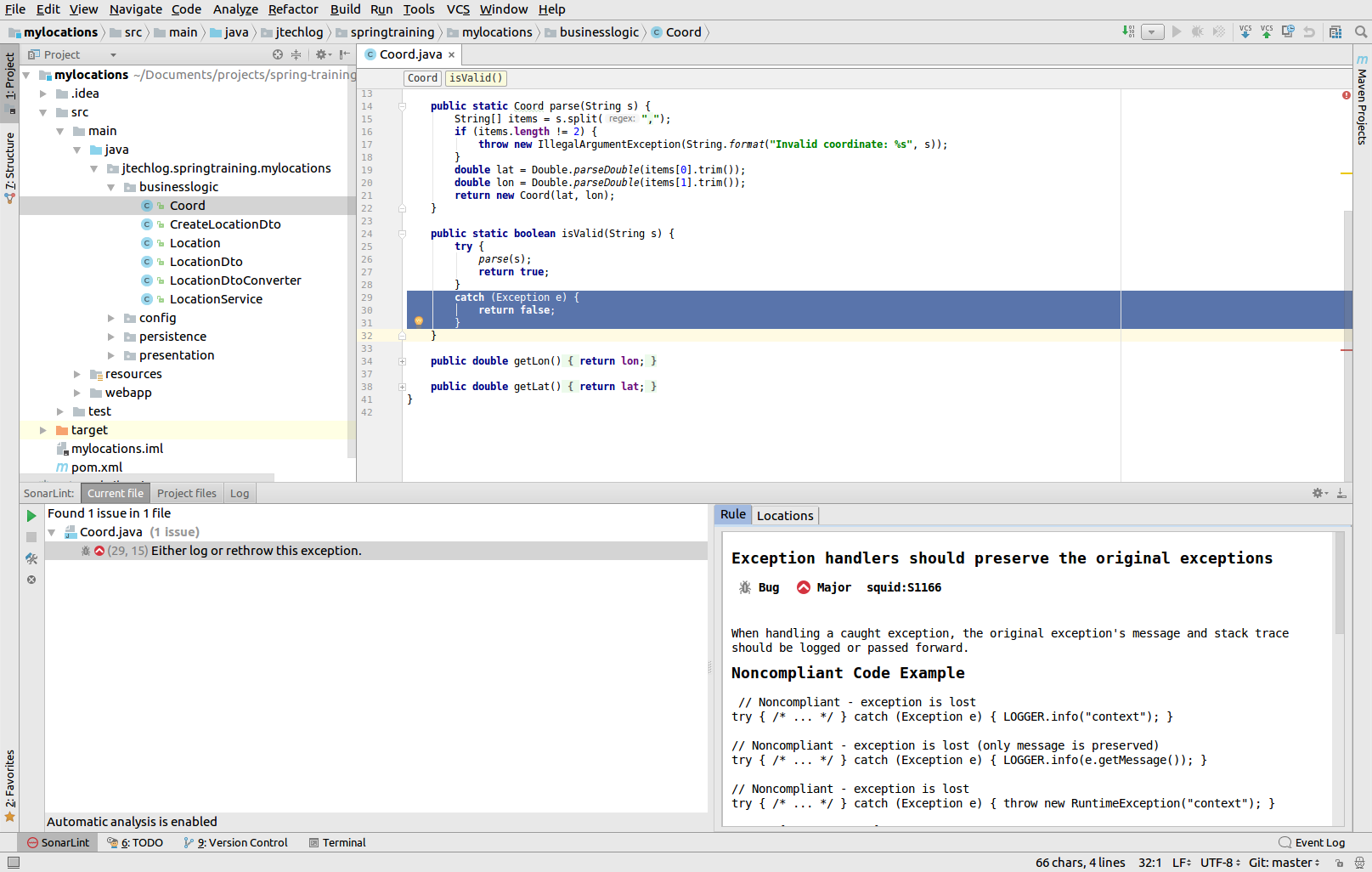
Amennyiben a klasszikus módszert használjuk, az új forráskód publikálásához képest nagyon későn jutunk az elemzés eredményére, ugyanis ki kell várnunk a Continuous Integration build futását, az elemzést a teljes projektre. Ebben segít nekünk a SonarLint IDE plugin, mely minden neves fejlesztőeszközhöz elérhető. Ez futtatható magában is akár a teljes projektre, akár csak a módosított fájlokon (verziókezelő rendszer alapján). De ún. Connected módban képes csatlakozni a SonarQube Serverhez, és onnan letölteni az adott projekthez a Quality Gate beállításokat, és az alapján futni, így értelmezni, hogy mely szabályok vannak bekapcsolva, és azok milyen szintűek. (Ez ugye csak úgy volt megvalósítható, hogy a SonarLint is a SonarQube Java Analyzert használja lokálisan a hibák felderítésére.) Ha változnak a Serveren a szabályok, csak a Update Bindings gombot kell megnyomni, így automatikusan frissül az IDE-ben is.
Az elemzés futtatása során megjelöli a hibás utasításokat, és a szabály azonosítóját és részletes leírását is megjeleníti.
Ez nagy mértékben gyorsíthatja a munkát, hiszen a forráskód publikálása előtt már azonnal ki lehet javítani a hibákat, szabálysértéseket, gyanús kódokat, és nem kell végigvárni a Continuous Integration folyamatot.
SuppressWarnings
Mit tegyünk akkor, ha már a forráskód publikálása előtt találkozunk azzal, hogy az Analyzer hibásan jelöl aggályosnak egy kódrészletet. Egyrészt el kell gondolkodni, hogy az adott szabály projekt szinten értelmes-e. (Pl. dolgoztam olyan projektben, ahol minden publikus konstruktort és metódust megfelelően JavaDoc-kal kellett ellátni, de olyanon is, ahol egy sor dokumentációs megjegyzés nem szerepelt a kódban.) Amennyiben a szabály projekt szinten nem értelmezett, a Serveren kell kikapcsolni. Ha viszont csak az adott helyen riasztott az elemző tévesen, a forráskódban megjelölhetjük, hogy az adott osztályban, metódusban azt a szabályt ne vegye figyelembe, a @SuppressWarnings annotáció megadásával. Ennek paraméterként a szabály azonosítóját kell megadni (amit a SonarLint is kiír, valamint a Server felületen is több helyen megjelenik), és megadhatunk többet is. Így helyes a @SuppressWarnings("squid:S2078"), vagy a @SuppressWarnings({"squid:S2078", "squid:S2076"}) megadási mód is.
Ne essünk túlzásokba, azzal nem csökkentjük a Technical Debtet, ha mindenütt használjuk ezt az annotációt, sőt csak elfedjük a problémákat a SonarQube elől.