Gondolatok a modell osztályokról, entitásokról, DTO-król
Nagyon szeretem azokat az írásokat, melyek különböző területekről származó fogalmakat próbálnak valamilyen egységes rendszerbe foglalni, a fogalmaknak egységes elnevezést adni. Ilyen volt a Tom Hombergs - Get Your Hands Dirty on Clean Architecture (2nd edition) könyv, mely a modell osztályokkal próbálta ezt tenni. Különösen tetszett, hogy nem egy megoldást fogad el igaznak, hanem ismerteti a különböző megoldásokat, összehasonlítva azok előnyeit és hátrányait.
A mostanában fejlesztett alkalmazások vagy a klasszikus háromrétegű (3-layer) architektúrával készülnek, vagy a modernebb Hexagonal vagy Clean Architecture-t használják.
Egy klasszikus Spring Boot alkalmazás esetén a három réteg a repository, service, controller. Java EE esetén ez a web, üzleti és EIS (Enterprise Information System) rétegek. Én egységesen úgy fogok rájuk hivatkozni, hogy prezentációs, üzleti logika és perzisztens réteg.
Clean Architecture esetén is megjelennek ezek, az alapvető különbség a függőségek irányában van, hiszen amíg a klasszikus háromrétegű alkalmazás esetén az üzleti logika réteg függ a perzisztens rétegtől, addig a Clean Architecture esetén a perzisztens réteg függ az üzleti logika rétegtől.
Minden rétegben szükség van azonban az adatokat tároló osztályokra, nevezzük ezeket modell osztályoknak. Manapság ezek egyszerű POJO (Plain Old Java Object) osztályok, pár attribútummal, konstruktorokkal, getter/setter metódusokkal.
Kérdés, hogy ebbe a fogalomrendszerbe hogyan illeszkednek be az entitások, DTO-k, stb.? Melyik rétegben helyezkednek el? Illetve kell-e, és hogyan kell ezek között a megfeleltetést elvégezni (mapping), konvertálni? Ez a poszt ebben próbál egyfajta rendet tenni.
Architektúrák
Az első ábran vizuálisan hasonlítjuk össze a két architektúrát. A háromrétegű architektúránál a szokástól eltérően nem egymás alatt, hanem egymás mellett ábrázoljuk a rétegeket, a könnyebb összehasonlíthatóság kedvéért. A balról jobbra mutató nyilak a függőség irányát, de a hívás irányát is mutatják.
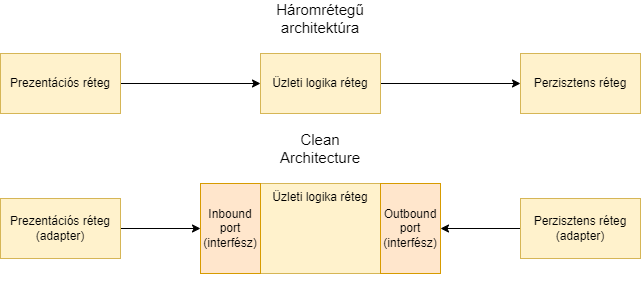
A Clean Architecture esetén középen van a üzleti logika réteg, és erre hivatkozik a prezentációs és a perzisztens réteg is, tehát látható hogy a függőség a perzisztens rétegnél megfordul. A hívás iránya viszont nem változik, ugyanúgy balról jobbra. A továbbiakban a nyilakat szándékosan nem fogom feltüntetni. A Hexagonal Architecture még tovább megy elnevezésekben, az üzleti logika réteg definiálja ezen kívül a portokat is. Ezek interfészek a többi réteg számára. A bejövő portok (inbound) azok az interfészek, melyeken keresztül az üzleti logikát lehet meghívni, ezeket az üzleti logika implementálja. A kimenő portok (outbound) pedig azok, melyeken keresztül az üzleti logika hív ki. Az adapterek melyek a külvilággal tartják a kapcsolatot (felhasználók, web, adatbázis), az interfészeken keresztül kommunikálnak, vagy akár meg is valósítják azokat. Ezért nevezik ezt az architektúrát Ports & Adapters architektúrának is.
Abban talán egységes az álláspont, hogy az üzleti logika rétegben szereplő modell osztályokat üzleti entitásnak nevezik. Egyedi azonosítóval rendelkeznek, és módosíthatóak. Ezek lehetnek üzleti logikát nem tartalmazó, csak attribútumokkal és getter/setter metódusokkal ellátott osztályok. Ez az ún. anemic (vérszegény) model. De a modernebb architektúrák, valamint a gyakran velük együtt használt DDD (Domain Driven Design) is azt preferálja, hogy az üzleti entitások egy rich (gazdag, üzleti logikával ellátott) modellt alkossanak.
Ezektől azonban nem feltétlenül elvárt, hogy perzisztálhatóak legyenek. Persze lehetnek olyan entitások is, melyeket perzisztálni lehet. Gyakran használunk erre valamilyen ORM eszközt, pl. a JPA-t, mely szerencsétlen módon a perzisztálható osztályokat szintén entitásnak nevezi, ezáltal összemosva a két fogalmat. Én ezekre perzisztens entitásokként fogok hivatkozni.
Stratégiák
A legegyszerűbb persze, ha ugyanazt az üzleti entitást használjuk az összes rétegbe. Ekkor nincs szükség megfeleltetésre sem. Ezt a könyv No Mapping stratégiának hívja.
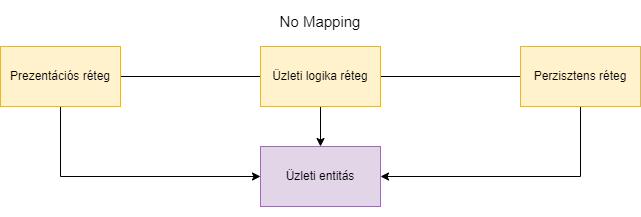
Ebben az esetben képzeljünk el egy Employee entitást, mely el van látva JPA és JSON annotációkkal is,
és ez utazik metódus paraméterekben és visszatérési értékként is.
Előnye, hogy rendkívül egyszerű, hiszen nincs szükség a mappingre. Hátránya, hogy megtöri a Single Responsibility elvet, hiszen az üzleti adattárolásért, JSON reprezentációért és adatbázis megfeleltetésért is felelős. Ha változik az entitás, akkor nagy eséllyel változik a JSON dokumentum és a táblaszerkezet is.
A következő stratégia, mikor minden rétegnek saját modellje van, ezt a könyv Two-Way Mapping stratégiának hívja.
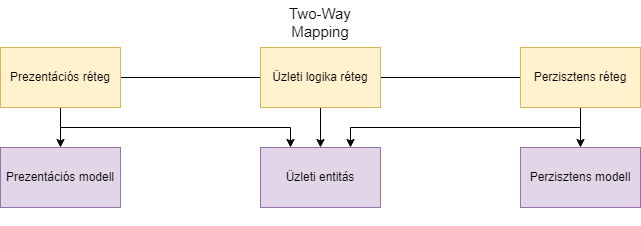
Ekkor természetesen szükség van a mappingre. A kérdés, hogy mely modell utazik a rétegek között, hol történik a mapping. Ebben az esetben az üzleti entitás szokott utazni, és a prezentációs és perzisztens réteg is hivatkozik rá, valamint ezekben a rétegekben történik a mapping is. Azaz az üzleti entitás elhagyja a saját rétegét.
Kérdés lehet ilyenkor, hogy hogyan hívjuk a prezentációs és perzisztens rétegben lévő modell osztályainkat.
A későbbi magyarázat miatt tartózkodnék a DTO elnevezéstől, mindenképp a használt technológia fogalmaira építenék.
Ez REST esetén lehet pl. Resource, SOAP webszolgáltatások, RPC alapú kommunikáció (pl. gRPC) vagy
aszinkron üzenetküldés esetén lehet pl. Request és Response. Klasszikus webes alkalmazásoknál Form és View / PresentationModel.
JPA adatbáziskezelés esetén marad az Entity.
Képzeljük el, hogy az üzleti entitásunk lesz az Employee, a prezentációs rétegben egy EmployeeResource és a
perzisztens rétegben egy EmployeeEntity. Az Employee üzleti entitás és a másik kettő között kell konvertálgatni.
Itt már nincs szoros kapcsolat a modellek között, azonban aggályos lehet, hogy az üzleti entitás kikerül az üzleti logika rétegből. Nyilván a mapping egy plusz komplexitást hoz.
A következő, mikor az üzleti entitás a üzleti logika rétegen belül marad, és a metódusok paraméterei és visszatérési értékei külön osztályok, még szintén az üzleti logika rétegben elhelyezkedő input/output modell. Ez a Full Mapping.
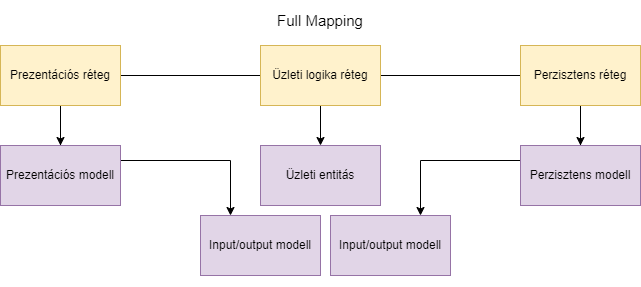
Ekkor az üzleti rétegben megjelenik az input/output modell, melyek adják a metódusok paramétereit, valamint a visszatérési
típusokat. Használhatóak itt pl. a Command, Query, Result elnevezések.
Képzeljük el, hogy bejön REST interfészen POST-tal egy EmployeeResource kérés,
ezt kell mappelni CreateEmployeeCommand input modellé, majd ez alapján hozunk létre egy Employee üzleti entitást.
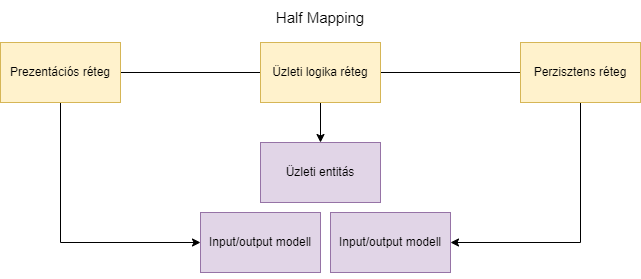
(Zárójelben megjegyzem, hogy én olyat is szoktam csinálni, hogy a prezentációs rétegnek nem hozok létre saját modellt, hanem teljes mértékben az input/output modellt használom erre a célra. Bár a könyvben ez nem szerepel, ezt önkényesen Half Mapping stratégiának nevezem.)
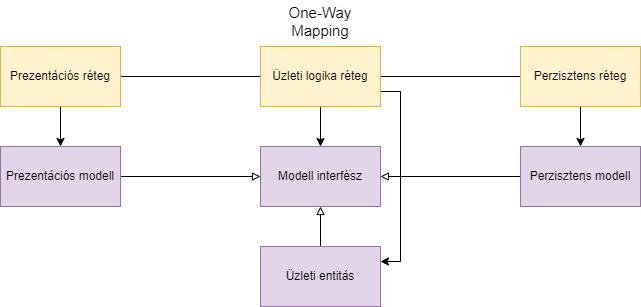
A könyv említ egy olyan megoldást is, mikor bevezet egy közös modell interfészt, melyet az összes modell implementál. Ez csak getterekkel rendelkezik. Így a paramétereknél és a visszatérési értékeknél lehet ezt az interfészt használni, nem tudjuk, hogy pontosan milyen példány van mögötte. Ezt One-Way Mapping stratégiának hívja.
Változatok
A dolgot még bonyolítja az, hogy a stratégiaválasztásnak egyáltalán nem kell szimmetrikusnak lennie, azaz a prezentációs réteg felé használhatunk más stratégiát, mint a perzisztens réteg felé.
Hiszen nagyon gyakori, hogy a prezentációs rétegből beérkező modellt még mappeljük üzleti entitássá, de az üzleti entitás maga egy JPA entitás is, ami azonnal menthető. Így a prezentációs réteg felé van egy Half Mapping, míg a perzisztens réteg felé egy No Mapping.
Amennyiben modernebb architektúrát alkalmazunk DDD-vel, ott a perzisztenciát ennél élesebben javasolják elkülöníteni. Azaz a üzleti entitások, domain entity-k kizárólag Java SE hivatkozásokat tartalmazhatnak, nem lehet kapcsolatban más technológiával, pl. JPA-val. Így ilyenkor külön perzisztens entitásokat szoktak létrehozni, üzleti entitást ebbe mappelni, és lementeni. Így az üzleti entitás változtatása nem hozza feltétlen magával az adatbázis módosítást, ráadásul a kettő szignifikánsan eltérhet.
Külön érdekesség még, hogy nem csak rétegek szerint, hanem irány szerint is használhatunk más mapping stratégiát. Pl. módosítás (CQS vagy CQRS esetén command) ágon használhatunk pl. Half Mappinget. Míg lekérdezés (query) ágon akár No Mappinget, azaz natív query-vel már olyan osztályt állítunk elő, amit azonnal viszünk végig a prezentációs rétegig.
Mikor melyiket használjuk?
A klasszikus válasz: attól függ. Egyszerű CRUD alkalmazás esetén használhatjuk a No Mapping stratégiát. Amikor azonban két réteg modellje eltér egymástól, a Full Mapping lehet jó választás.
Érdemes megjegyezni, hogy ezt ne véssük kőbe. Indulhatunk a No Mapping stratégiával, és ahogy változik az alkalmazás, úgy vezetünk be más stratégiát.
További megfontolások
JPA használata esetén amennyiben a JPA entitás átkerül másik rétegbe, oda kell figyelnünk. Ugyanis a tranzakciós határon belül módosíthatjuk az állapotát. Ez üzleti logika rétegben lehet akár előnyös, ugyanis nem kell a módosítás után külön metódust hívni, hiszen a JPA automatikusan visszaszinkronizálja az adatbázisba. Ha az üzleti logika réteg biztosítja a tranzakciós határt, akkor nem kell félni, hogy a prezentációs réteg módosítja az entitás állapotát, és azt a JPA szinkronizálja az adatbázisba.
Bár a JPA szabvány szerint a perzisztens entitások pehelysúlyú komponensek, POJO-k, egy probléma azonban adódik, méghozzá a lazy loading, szóval sajnos POJO-ink nem függetlenek az adatbázistól. Ha egy perzisztens entitáshoz kapcsolódó más entitásokhoz akarunk hozzáférni a tranzakciós határon kívül, kivételt kaphatunk. Ezért nekünk kell gondoskodnunk arról, hogy az összes kapcsolódó entitás betöltésre kerüljön, azaz pl. fetch joinnal betölteni.
Nem érdemes ugyanazt az input/output modell osztályt használni különböző használati eseteknél.
Szóval pl. elgondolkozhatunk, hogy ugyanazt az EmployeeCommand osztályt használjuk alkalmazott
létrehozásánál és módosításánál is. Csak bizonyos attribútumokat kitöltünk, bizonyos attribútumokat nem.
Javasolt inkább egy RegisterEmployeeCommand és egy UpdateEmployeeCommand modell osztályt létrehozni.
Ezáltal teljesül a Single Responsibility, másrészt a forráskód is olvasható marad, hiszen már az osztály
nevéből látszik, hogy mely használati esetben vesz részt.
REST esetén azonban ez megfontolandó, ugyanis a REST szabvány szerint mindig a teljes erőforrás utazik (, és nem annak egy részhalmaza). Ott nincsenek ugyanis külön metódusok, URL-ekben nem használhatunk igéket, csak az erőforrások, és az azokon végzett CRUD műveltek léteznek.
Mi van akkor, ha különböző képernyőkön az entitás adatainak különböző részhalmazait szeretnénk megjeleníteni. Itt is dönthetünk úgy, hogy minden adatot leküldünk, és a UI kiválogatja a megfelelő mezőket. Azonban bonyolult entitások esetén érdemes lehet performancia okokból több modellt is létrehozni képernyőnként.
Ha ezt ráadásul hatékonyan akarjuk megtenni, dönthetünk amellett, hogy pl. JPA projection query-t, vagy native query-t (akár JDBC-vel) használunk.
Használhatunk REST helyett GraphQL-t is, mely erre a feladatra sokkal jobb választás.
A modell osztályoknak technológiai megszorításai is lehetnek. Pl. egy JPA perzisztens entitásnak lennie kell paraméter nélküli konstruktorának. Sokszor gondolkodás nélkül létrehozzuk a paraméter nélküli konstruktort, valamint az összes getter/setter metódust. Érdemes utánanézni a különböző technológiák dokumentációjában, ugyanis a Hibernate képes privát konstruktorral is, és getter/setter metódusok nélkül is dolgozni.
Persze előfordulhat, hogy hívó és hívott oldalon is ugyanazokat az osztályokat akarjuk használni, két különböző alkalmazásban. Ekkor eszünkbe juthat, hogy úgy osszuk meg ezeket az osztályokat, hogy egy külön JAR-ba csomagoljuk, és mindkét alkalmazásban felhasználjuk. Ezt a megoldást lehetőleg kerüljük, mert nagy függőség, inkább függjünk az API-leírástól, pl. REST esetén az OpenAPI dokumentumtól, SOAP esetén a WSDL-től, más technológia (gRPC + Protocol Buffer, GraphQL) esetén bármilyen séma leírástól, amiből akár forráskód is könnyen generálható.
A modellek használatának további csomagolási vonzata is lehet. Ugyanis elképzelhető, hogy úgy akarjuk egy alkalmazáson belül korlátozni, hogy mely osztályhoz csak mely rétegek férhetnek hozzá, hogy külön modulba, esetleg JAR-ba tesszük őket.
DTO
A Data Transfer Object kifejezés konkrétan Martin Fowlertől származik, és a Patterns of Enterprise Application Architecture könyvében már megjelent 2002-ben. Feltételezhetően innen vette át a Core J2EE Patterns könyv is, bár ott csak Transfer Object néven szerepel.
Az elsődleges feladata a hálózati kommunikáció csökkentése távoli hívás esetén (RMI). Ugyanis ha az adatok túl finom szemcsézettségűek, és emiatt csak sok hívással lehet átvinni, az hálózati kommunikáció szempontjából költséges. Megoldás a DTO használata, amivel nagyobb darabokba fogjuk össze az adatokat, és kevesebb, ideális esetben egy hívással visszük át a hálózaton.
Másik problémaként jelentkezett, hogy bizonyos technológiák esetén (ilyen pl. a J2EE Entity Beanek), az entitások túlságosan kötődtek az adatbázishoz, nehézsúlyú komponensek voltak, és nem lehetett ezeket szerializálni, és így átvinni ezeket a hálózaton.
Ezt a mintát az alkotója szerint is sokan félreértették, és ki is kelt ez ellen a LocalDTO írásában. Itt odáig is elmegy, hogy lokális esetben (ilyen lehet, ha az alkalmazáson belül a prezentációs és üzleti réteg közötti átvitelre használjuk) nem hogy nem hasznos, de plusz költség, már-már károsnak tekinthető.
Megemlíti, hogy ezzel biztosítható, hogy az üzleti logika réteg módosítható legyen anélkül, hogy a kliensre hatással legyen, azonban ne felejtsük el a mapping költségét, ami “jelentős és fájdalmas is lehet”. (Gondoljunk itt a ModelMapper és MapStruct használatára.)
Azt azonban később elismeri, hogy abban az esetben, ha a prezentációs réteg modellje és a domain model jelentősen eltér, akkor használhatunk valami mappinget, és utal a Presentation Model mintára, mely gyakorlatilag olyan modell a GUI rétegben, mely annak igényei szerint van felépítve.
Ezt érthetjük úgy is, hogyha konvertáljuk is az entitásokat, ne a DTO nevet használjuk, mert az nem ezt takarja. Azonban a világ már túllépett ezen, és sokszor használják ilyenkor a DTO elnevezést.