Project Reactor és a szálkezelés
A Project Reactor egy Springhez közel álló reaktív könyvtár. Erre épül a Spring Framework 5-ben megjelent WebFlux webes keretrendszer
reaktív webes alkalmazások készítésére. Ez nagyban hasonlít a Spring MVC-re, azonban reaktív módon működik.
Ezzel találkozhatunk akkor is, ha WebClient-et használunk REST webszolgáltatások hívására
(ez a RestTemplate-et hivatott leváltani, de úgy tűnik, hogy mégis szükség van egy szinkron megvalósításra is,
ezért jelent meg a 6.1-es Spring Frameworkben a RestClient). A reaktív elvekről és keretrendszerekről
már írtam a Reaktív programozás posztomban.
A Reactor ún. concurrency-agnostic, ami azt jelenti, hogy nem erőltet ránk semmilyen párhuzamossági modellt. Azonban a fejlesztőnek lehetőséget ad a szálak használatára.
Ez a poszt azzal foglalkozik, hogy lehet szálakat használni, hogyan befolyásolja a szálak
használatát a publishOn és subscribeOn operátor (Mono és Flux osztályokban lévő metódusok).
A poszthoz tartozó példaprogram megtalálható a GitHubon.
Bevezetés
Kezdjük egy egyszerű teszt esettel.
@Test
void onMainThread() {
var upperCaseNames = Flux.fromIterable(employees)
.filter(employee -> employee.getYearOfBirth() >= 1980)
.doOnNext(e -> log.info("filter"))
.map(Employee::getName)
.doOnNext(e -> log.info("map - getName"))
.map(String::toUpperCase)
.doOnNext(e -> log.info("map - toUpperCase"))
;
log.info("Pipeline is ready");
StepVerifier.create(upperCaseNames)
.expectNext("JACK DOE")
.expectNext("JANE DOE")
.verifyComplete()
;
}
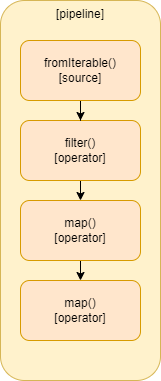
A streameket ismerve könnyen olvasható a forráskód, ami az alkalmazottak listájából kiszűri az 1980 előtt születetteket, majd lekéri azok neveit, és nagybetűsíti.
A forrás a fromIterable(), mely visszaad egy Flux-ot, ami önmaga implementálja a Publisher
interfészt (lásd előző posztomban a Reactive Streams elméletét és részeit).
Ez után helyezhetjük el az operátorokat, kialakítva így egy futószalagot, vagy csővezetéket, ez a pipeline, vagy operator chain (lánc). Ez az ún. deklaratív fázisban történik, ez az assembly time.
Itt valójában három fő operátor szerepel egymás után: filter, map, map. A doOnNext() operátoroktól
most tekintsünk el, hiszen azok csak naplóznak, hogy lássuk, hogy azt épp milyen szál futtatja.
A teszteset StepVerifier-t használ az ellenőrzésre.
Amit még érdemes tudni, hogy ugyan elkészül a pipeline, azonban semmi nem történik addig, amíg
meg nem történik a tényleges feliratkozás (Nothing Happens Until You subscribe()).
A feliratkozás alkalmával a feliratkozó jelez (signal) az előtte lévő operátornak,
az szintén az előtte lévő operátornak, és így tovább. Így létrejön egy subscription chain.
Majd ezután indulnak el az elemek a pipeline-on. Ez az execution time.
A feliratkozást itt a StepVerifier végzi.
Ezért van az, hogy először kerül kiírásra a Pipeline is ready szöveg, és csak azután
a doOnNext() paramétereként átadott lambda kifejezésben lévő szövegek.
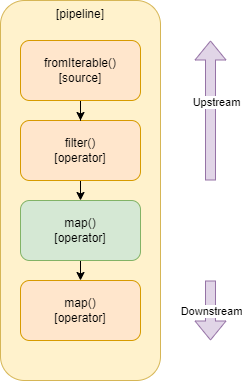
Érdemes még ismerni az upstream és downstream fogalmát, ugyanis az operátorok dokumentációja gyakran hivatkozik erre. Egy operátor szempontjából upstream az operátort megelőző stream, és downstream.
Alapértelmezett szálkezelés
Ha lefuttatjuk a teszt esetet, látható, hogy a main szálon kerül lefuttatásra.
Valójában azon szálon kerülnek lefuttatásra az operátorok, amelyik szálon megtörtént a feliratkozás.
Azaz ha a StepVerifier-t új szálon futtatjuk, akkor minden azon az új szálon fog futni.
var anotherThread = new Thread(() -> StepVerifier.create(upperCaseNames)
.expectNext("JACK DOE")
.expectNext("JANE DOE")
.verifyComplete())
;
anotherThread.start();
anotherThread.join();
Ezzel létrehozunk, elindítunk egy új szálat, és bevárjuk azt. A végrehajtás a Thread-0
szálon fog futni.
Szálakat módosító operátorok
Vannak olyan operátorok, melyek szálat váltanak, ilyen pl. a delaySequence().
var upperCaseNames = Flux.fromIterable(employees)
.filter(employee -> employee.getYearOfBirth() >= 1980)
.doOnNext(e -> log.info("filter"))
.map(Employee::getName)
.doOnNext(e -> log.info("map - getName"))
.delaySequence(Duration.ofMillis(10))
.map(String::toUpperCase)
.doOnNext(e -> log.info("map - toUpperCase"))
;
A delaySequence()-t követő map() operátor itt már a parallel-1 szálon fog futni.
publishOn() operátor használata
A publishOn() metódus hatására az azt követő operátor már más szálon kerül meghívásra.
Paraméterül egy Scheduler implementációt kell átadni, mely hasonló absztrakció, mint
az ExecutorService. A Scheduler tartalmaz több schedule() metódust, melynek
a végrehajtandó feladatot kell átadni. A Schedulers tartalmaz több factory metódust, mellyel
Scheduler példányokat lehet létrehozni. Ilyenek pl.:
Scheduler.parallel()- állandó méretű thread poollal dolgozó schedulerScheduler.boundedElastic()- olyan thread poolal dolgozó scheduler, amely mérete növekedhet, de korlátosScheduler.single()- egy újrafelhasználható szállal dolgozó schedulerScheduler.immediate()- nem vált szálat
Mindegyiknek van egy new szóval kezdődő változata is. A parallel() hívás első alkalommal elkészíti a Scheduler-t, majd mindig
ugyanazt adja vissza, addig a newParallel() mindig új Scheduler példányt hoz létre.
A publishOn() használatát mutatja be az alábbi kódrészlet:
var upperCaseNames = Flux.fromIterable(employees)
.filter(employee -> employee.getYearOfBirth() >= 1980)
.doOnNext(e -> log.info("filter"))
.publishOn(Schedulers.newParallel("p1"))
.map(Employee::getName)
.doOnNext(e -> log.info("map - getName"))
.map(String::toUpperCase)
.doOnNext(e -> log.info("map - toUpperCase"))
;
Ekkor a filter a main szálon fut, majd a publishOn() szálat vált, és a további operátorokat már a p1 Scheduler futtatja.
publishOn() operátor többszöri használata
Amennyiben több publishOn() hívás van, többször történik meg a szál váltása, hiszen a publishOn() hat
az utána következő operátorra.
var upperCaseNames = Flux.fromIterable(employees)
.filter(employee -> employee.getYearOfBirth() >= 1980)
.doOnNext(e -> log.info("filter"))
.publishOn(Schedulers.newParallel("p1"))
.map(Employee::getName)
.doOnNext(e -> log.info("map - getName"))
.publishOn(Schedulers.newParallel("p2"))
.map(String::toUpperCase)
.doOnNext(e -> log.info("map - toUpperCase"))
;
Ekkor a filter() a main szálon fut, a map()-et a p1, míg a következő map()-et már a p2 fogja futtatni.
Azaz kijelenthező, hogy a publishOn() az operátort követő operátorokra van hatással, egészen a következő
publishOn() hívásig.
subscribeOn() operátor
A subscribeOn() operátor dokumentációja elég rejtéjes, azt mondja, hogy a subscribe(), onSubscribe() és a request()
kerül más szálon meghívásra. De mi ennek a jelentősége? Az, hogy ilyenkor valójában a hatás a teljes streamre vonatkozik a
source-tól kezdődően.
var upperCaseNames = Flux.fromIterable(employees)
.filter(employee -> employee.getYearOfBirth() >= 1980)
.doOnNext(e -> log.info("filter"))
.map(Employee::getName)
.doOnNext(e -> log.info("map - getName"))
.map(String::toUpperCase)
.doOnNext(e -> log.info("map - toUpperCase"))
.subscribeOn(Schedulers.newParallel("s1"))
;
Attól függetlenül, hogy a subscribeOn() az utolsó operátor, az összes operátort az s1 fogja futtatni!
Ez független attól, hogy hova tesszük a subscribeOn() hívást. Azaz ez a kód is ugyanazt a működést eredményezi:
var upperCaseNames = Flux.fromIterable(employees)
.subscribeOn(Schedulers.newParallel("s1"))
.filter(employee -> employee.getYearOfBirth() >= 1980)
.doOnNext(e -> log.info("filter"))
.map(Employee::getName)
.doOnNext(e -> log.info("map - getName"))
.map(String::toUpperCase)
.doOnNext(e -> log.info("map - toUpperCase"))
;
subscribeOn() operátor többszöri használata
Amennyiben a subscribeOn() metódust többször használjuk, csak az első hívásnak
lesz hatása, a többinek nem.
var upperCaseNames = Flux.fromIterable(employees)
.filter(employee -> employee.getYearOfBirth() >= 1980)
.doOnNext(e -> log.info("filter"))
.subscribeOn(Schedulers.newParallel("s1"))
.map(Employee::getName)
.doOnNext(e -> log.info("map - getName"))
.map(String::toUpperCase)
.doOnNext(e -> log.info("map - toUpperCase"))
.subscribeOn(Schedulers.newParallel("s2"))
;
És bár van subscribeOn() hívás rendre s1 és s2 Scheduler-rel, minden operátort az s1 fogja futtatni.
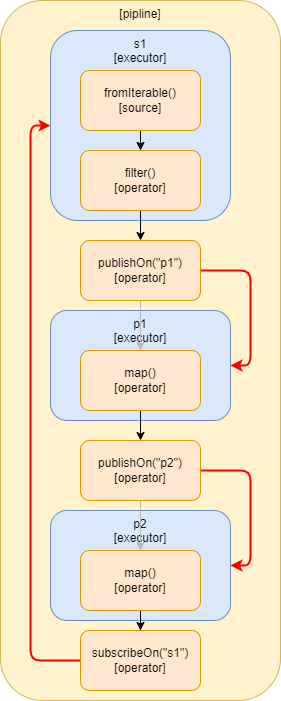
publishOn() és subscribeOn() keverése
Ha a publishOn() és subscribeOn() operátorokat együtt használjuk, akkor a
subscribeOn() a stream elejétől hat egészen az első publishOn()-ig, ami
szálat vált, egészen a következő publishOn()-ig, ami ismét szálat vált.
var upperCaseNames = Flux.fromIterable(employees)
.filter(employee -> employee.getYearOfBirth() >= 1980)
.doOnNext(e -> log.info("filter"))
.publishOn(Schedulers.newParallel("p1"))
.map(Employee::getName)
.doOnNext(e -> log.info("map - getName"))
.publishOn(Schedulers.newParallel("p2"))
.map(String::toUpperCase)
.doOnNext(e -> log.info("map - toUpperCase"))
.subscribeOn(Schedulers.newParallel("s1"))
;
Így a filter()-t az s1 futtatja, a map()-et a p1 és a következő map()-et pedig a p2.
Ez grafikusan is igen jól ábrázolható.