Reaktív programozás
A reaktív programozás mostanában elég pezsgő irányzat, melynek fejlődését érdemes nyomon követni. A reaktív programozás mibenlétéről megoszlanak a vélemények. Amit azonban először érdemes megemlíteni, a Reaktív Kiáltvány (The Reactive Manifesto).
A kiáltvány szerint a modern alkalmazásokkal kapcsolatban már más nem funkcionális követelmények merülnek fel, pl. válaszidő, rendelkezésre állás, adatmennyiség, skálázhatóság és hibatűrés tekintetében, valamint más környezetekben futnak, a felhő és konténerizáció nagyon elterjedt.
Ezen alkalmazásoknak négy jellemzőjét definiálja a kiáltvány, melyek a következők:
- Reszponzív (Responsive): az alkalmazásnak minden esetben gyors választ kell adnia
- Ellenálló (Resilient): az alkalmazás gyorsan válaszoljon hiba esetén is
- Rugalmas (Elastic): az alkalmazás gyorsan válaszoljon nagy terhelés esetén is
- Üzenetvezérelt : rendszerek elemei aszinkron, nem blokkoló módon, üzenetekkel kommunikálnak
Reaktív programozás használatakor az alkalmazást úgy építjük fel, hogy az az adatok aszinkron folyamára reagáljon. Ezen adatfolyamok lehetnek a felhasználói interakciók, más alkalmazásoktól vagy (pl. IoT) eszközöktől érkező üzenetek.
Az első három feltétel elég általános, talán az üzenetvezéreltség némileg technológiaibb. Ennek segítségével lehet megoldani a rendszer komponensei közötti laza kapcsolatot. Megvalósítható vele a lokális transzparencia, azaz a komponensek helyzetüktől függetlenül szólíthatók meg. Egyszerűbbé válik a hibakezelés, pl. a hálózati kiesés. Segít a terheléselosztásban, skálázhatóságban. Valamint megóvhatja a komponenseket a túlzott terheléstől.
Ebben a posztban szó lesz a reaktív programozás kialakulásáról, tulajdonságairól, irányvonalairól, különböző eszközökről, szabványosításáról, valamint hogyan használhatjuk Springen belül.
A példaprojekt elérhető GitHubon.
Történeti háttér
A Reaktív Kiáltvány betartását számos tényező hátráltatja.
Ebből a legfontosabb a szinkron IO használata. Ez szinte az alkalmazás összes rétegében tetten érhető. Egyrészt a web konténer megvárja, míg beérkezzen a teljes HTTP kérés, és ezt szinkron szolgálja ki. Más rendszerek SOAP vagy REST webszolgáltatását szinkron módon hívja. A fájlt a fájlrendszerből szinkron módon olvassa be. Az adatokat az adatbázistól szinkron módon kéri le.
Érdekes módon Javaban már az 1.4-es verziótól kezdve van erre megoldás, a Java NIO (New IO, vagy másnéven Non-blocking IO)
személyében. Ez az operációs rendszer lehetőségeit használja ki,
elindítja a műveletet, pl. socketről olvasást, de nem várja meg az eredményt, hanem egy callbacket ad át,
mely visszahívásra kerül a művelet befejezésekor, és ezzel jelentős mennyiségű CPU időt takarít meg.
Ide kapcsolódnak a következő Java interfészek és osztályok: java.nio.Buffer, pl. ByteBuffer,
java.nio.channels.Channel, pl. AsynchronousFileChannel.
Sajnos azonban ez kevésbé elterjedt. Adatbáziskezelésre JDBC-t és rá épülő JPA-t használunk, mely szintén szinkron. A webes kiszolgálás Servlet API-val történik, valamint erre épülő szabványokra és keretrendszerekre (JSF, JAX-WS, JAX-RS, Spring MVC), melyek szintén szinkron módon működnek. Vannak ugyan erre épülő keretrendszerek, mint a Netty, de ezek kevésbé elterjedtek.
Az alkalmazások gyakran kollekciókon dolgoznak (List, Set, Map, stb.), melyek elemeit teljes mértékben
betöltjük a memóriába, és így dolgozunk rajta. Az Iterator és Stream használata már
előrelépés.
Tipikus webes alkalmazásnál, ami a Servlet API-ra épül minden kérésnél egy új szál kerül elindításra. Itt szálanként 1 MB stack memóriafoglalással kell számolnunk, valamint a szálak közötti váltás (context switch) jelentős mennyiségű CPU időt visz el. Ráadásul a tranzakciókezelést is a szálakhoz kötjük.
A túlzott terhelés esetén gyakran előfordul, hogy a CPU az IO-ra vár, feltorlódnak a kérések, megnő a memóriahasználat, ennek hatására a GC több CPU-t használ, nő a context switch számossága, ami szintén a CPU-t terheli. Jobb esetben csak belassul minden kérés kiszolgálása, rosszabb esetben elkezdi eldobálni a kéréseket.
A megoldás
Amennyiben a termelő a saját ütemében állítja elő az adatot, túlterhelheti a fogyasztót, ez hálózati protokolloknál ismert jelenség, megoldása a flow control, vagy push back, melynek több implementációja is ismert.
Ahhoz, hogy a rendszer reszponzív tudjon maradni, meg kell akadályozni, hogy ezen elemek olyan ütemben érkezzenek be, hogy azok elárasszák a feldolgozó komponenst (fogyasztó), ezáltal az túlterhelődjön, belassuljon, esetleg hibázzon. Erre egy mechanizmus a back pressure, az ellenállóképesség az elárasztással szemben. Ennek egyik típusa a non-blocking back pressure, mely úgy oldja meg ezt a védelmet, hogy a feldolgozó komponens kéri el a következő elemeket az elemek forrásától (termelő), annyit, amennyit biztonságosan fel tud dolgozni, ezáltal megakadályozva a túlterhelést.
A reaktív programozást tipikusan funkcionális stílusban használjuk (functional reactive programming - FRP), ahol az alapegység a függvény. Ennek jellemzője, hogy deklaratív, ezáltal könnyebben olvasható, karbantartható és javítható. Apró egységekből, újrafelhasználható operátorokból komplex megoldásokat lehet elkészíteni. Mivel az alapegysége az állapotmentes, mellékhatásmentes függvények, könnyebben lehet vele párhuzamos algoritmusokat implementálni (könnyebben olvasható, kisebb a hibázás lehetősége).
Reaktív library-k
Ez az elv programozási nyelv független. A legtöbb programozási nyelvhez több reaktív library is elérhető, sőt vannak olyanok, melyek a legtöbb programozási nyelven elérhetőek és hasonlóan használhatóak (pl. ilyen a ReactiveX, Eclipse Vert.X). Ezen library-k Java nyelven is elérhetőek (pl. ReactiveX/RxJava), de vannak további Java közeli implementációk is, mint pl. az Akka, vagy a Project Reactor, mely a Spring mögött álló Pivotal megvalósítása.
Ezen library-k a funkcionális reaktív programozást teszik lehetővé, és a következőket ígérik:
- Olvashatóbb, karbantarthatóbb, hibamentesebb lesz a kód
- Sok boilerplate kód eliminálható
- Hibakezelést nem külön ágon kell megvalósítani, hanem a deklaratív leírás részét képzi
- Defacto standard megoldásokat lehet használni gyakran felmerülő problémákra
- Callback-hellt el lehet vele kerülni, melybe nem funkcionális programozás esetén, aszinkron hívásokkor hamar beleütközhetünk
Nézzük meg, hogy pl. egy alkalmazott listát hogyan szűrünk, transzformálunk a különböző library-kkal.
Pl. RxJava esetén:
Flowable.fromIterable(employees)
.filter(employee -> employee.getYearOfBirth() >= 2001)
.map(Employee::getName)
.map(String::toUpperCase)
.subscribe(System.out::println);
Project Reactor:
Flux.fromIterable(employees)
.filter(employee -> employee.getYearOfBirth() >= 2001)
.map(Employee::getName)
.map(String::toUpperCase)
.subscribe(System.out::println);
A Project Reactor támogatja a tesztelést is a StepVerifier segítségével:
StepVerifier.create(names) // Flux<String>
.expectNext("John Doe")
.verifyComplete();
Referenciaként álljon itt a Java 8-as megoldás streammel:
employees.stream()
.filter(employee -> employee.getYearOfBirth() >= 2001)
.map(Employee::getName)
.map(String::toUpperCase)
.forEach(System.out::println);
Látható, hogy mennyire hasonlóak a különböző library megoldásai, elemi
operátorokkal dolgoznak. Ezek ráadásul nagyon hasonlóak a Java 8 Stream API-ban
található operátorokhoz, annyi különbséggel, hogy ezen library-kban akár több száz ilyen
operátor is található. Ezek dokumentálása egységes, és nagyon látványos,
ún. marble diagramokkal dolgozik. Pl. itt látható a map() metódus diagramja.

Project Reactor
A Project Reactor azonban nem csak egy library, hanem egy teljes megoldás, ugyanis a következő modulok is hozzá tartoznak:
- Reactor Netty: HTTP, TCP, UDP kliens/szerver, Netty-re építve
- Reactor Kafka: Kafka integráció
- Reactor RabbitMQ: RabbitMQ integráció
Alapvetően a Mono és Flux nevezetű típusos adatfolyamokra épít, ahol mindkettő
implementálja a Publisher interfészt, és az előbbi nulla vagy egy elemet (mint a Java 8 Optional), míg
az utóbbi nulla vagy több elemet tartalmazhat (mint a Java 8 Stream). (Érdekes, hogy a kettő közötti
átjárhatóságot csak a Java 9-ben implementálták, ahol megjelent az Optional stream() metódusa.)
Reactive Streams
Azonban hamar felmerült az igény, hogy ezen library-kat össze lehessen egymással kapcsolni,
ehhez azonban közös interfészekre volt igény. Ezeket a Reactive Streams
kezdeményezésen belül alakították ki. A téma fontosságát mutatja,
hogy ez bekerült a Java 9-be Flow API néven (java.util.concurrent.Flow osztály belső
interfészei és osztályai). A következő osztályok és interfészek
kerültek kialakításra: Publisher, Subscriber, Subscription.
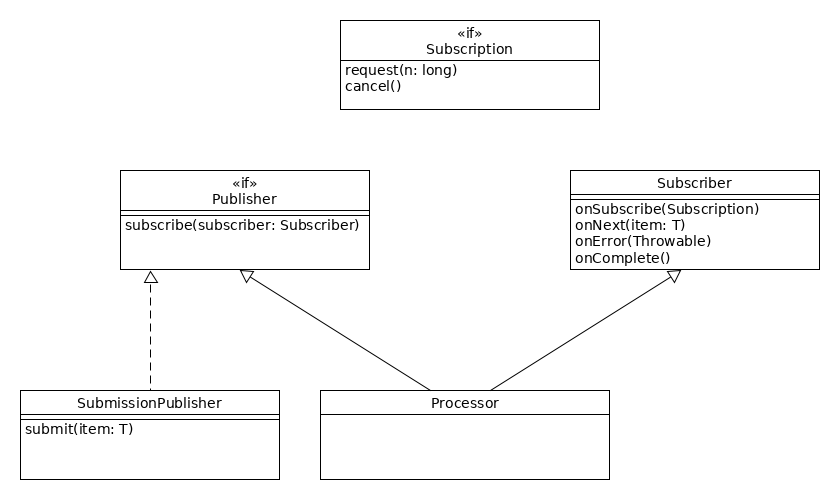
A Publisher mely az elemeket állítja elő. Erre egy Subscriber fel tud iratkozni,
ekkor jön létre egy Subscription objektum. Ezen keresztül lehet kérni a következő
elemeket a request() metódussal. Ennek hatására az elemek előállításra, majd
átadásra kerülnek, a Subscriber onNext() metódusának. Érdekesség még, hogy a java.util.Observable
Java 9-től deprecated, és a Flow API-t javasolja.
A Java standard osztálykönyvtárban ezen interfészeknek nincs sok implementációjuk, bár a JavaDoc
leírja, hogyan lehet ezeket megvalósítani. Egyedül a Java 11-ben megjelent, beépített aszinkron
nem-blokkoló java.net.http.HttpClient használja.
Az API megjelenésével nézzük meg, hogyan lehet egy RxJava-s Flowable-ből egy
Project Reactoros Flux-ot létrehozni (egy egyszerű from() metódussal).
Hiszen mindkettő implementálja a Publisher interfészt.
Flowable<String> names = Flowable.fromIterable(employees)
.filter(employee -> employee.getYearOfBirth() >= 2001)
.map(Employee::getName);
Flux.from(names)
.map(String::toUpperCase)
.subscribe(System.out::println);
Hiába van ilyen API-nk, egy reaktív architektúrát csak akkor tudjuk kihasználni, ha minden eleme aszinkron és nem-blokkoló. Azaz sem a webes keretrendszer, sem az adatbázishozzáférés nem lehet szinkron blokkoló.
Spring WebFlux
A Spring Framework 5 egyik legnagyobb újdonsága egy reaktív webes keretrendszer, a Spring WebFlux. Jellemzője, hogy aszinkron, nem blokkoló futást és funkcionális programozást tesz lehetővé a Project Reactorra építve, valamint a más platformokon bizonyító keretrendszerekhez hasonlóan a kiszolgálás kevés újrafelhasználható szálon történik (event loop workers).
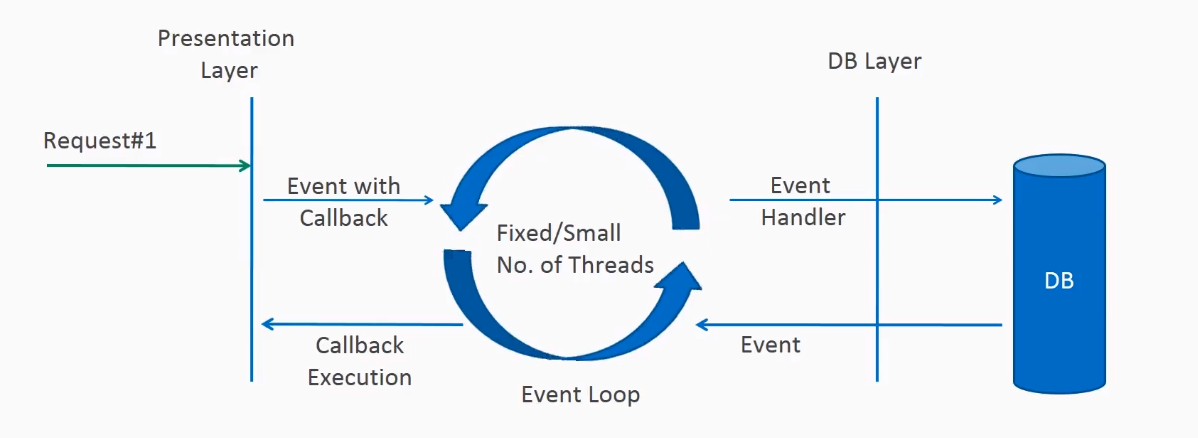
A Spring fejlesztői úgy döntöttek, hogy nem ágaztatják el a Spring MVC keretrendszer kódját, hanem a Spring MVC tapasztalataira építve vele párhuzamosan fejlesztik ki a Spring WebFluxot. Ez azonban már az alapokban eltér, ez ugyanis nem a Servlet API-ra épít, hanem a Reactive HTTP API-ra. (Ezt a keretrendszert használva Spring Boot esetén már nem a Tomcat, hanem a Netty lesz az alapértelmezetten beépített konténer.)
WebFlux esetén is lehet ugyanúgy controllereket létrehozni a @RestController, @GetMapping, stb.
annotációkkal.
@RestController
@RequestMapping("/api/employees")
public class EmployeeController {
private EmployeeService employeeService;
@GetMapping
public Flux<EmployeeDto> listEmployees() {
return employeeService.listEmployees();
}
@PostMapping
public Mono<EmployeeDto> createEmployee(@RequestBody Mono<CreateEmployeeCommand> command) {
return employeeService.createEmployee(command);
}
}
Látható, hogy itt a paraméterek és a visszatérési értékek Mono vagy Flux típusúak.
De ezek mellett alkalmazhatunk ún. router functionöket, melyekkel funkcionális módon adhatjuk meg, hogy melyik URL esetén mely függvény kerüljön meghívásra.
@Configuration
public class EmployeeController {
private EmployeeService employeeService;
@Bean
public RouterFunction<ServerResponse> route() {
return RouterFunctions
.route(RequestPredicates.GET("/api/employees"), employeeService::listEmployees)
.and(route(POST("/api/employees"), employeeService::createEmployee);
}
}
Perzisztens réteg R2DBC-vel
A NoSQL adatbázisoknál hamarabb találunk aszinkron nem-blokkoló drivert (pl. MongoDB esetén alapból ilyen), azonban a klasszikus JDBC driverek mind szinkron és blokkoló. Erre hozták létre a R2DBC projektet, melyben H2, PostgreSQL, Microsoft SQL Server és MySQL-hez van implementáció.
Ez a következőképp használható pl. H2 adatbázis esetén:
ConnectionFactory connectionFactory = ConnectionFactories
.get("r2dbc:h2:mem:///testdb");
Mono.from(connectionFactory.create())
.flatMapMany(connection -> connection
.createStatement("SELECT firstname FROM PERSON WHERE age > $1")
.bind("$1", 42)
.execute())
.flatMap(result -> result
.map((row, rowMetadata) -> row.get("firstname", String.class)))
.doOnNext(System.out::println)
.subscribe();
Ahhoz, hogy ezt ne kelljen ilyen alacsony szinten használni, a Spring Data irányelveihez illeszkedve
létrehozták a Spring Data R2DBC projektet is. Egyrészt biztosít egy DatabaseClient, melyen keresztül
funkcionális módon lehet hozzáférni az adatbázishoz. Ezen kívül a szokásos módon képes repository
interfészhez implementációt is generálni.
public interface EmployeesRepository extends ReactiveCrudRepository<Employee, Long> {
}
A tranzakciókezelés a klasszikus architektúra esetén deklaratív esetben a @Transactional
annotációval működik, és mögötte a szálhoz kapcsolt Transaction objektum áll (ThreadLocal-lal implementálva).
Itt is használható a @Transactional annotáció, de már más implementáció van mögötte.
A service rétegben történhet az entitás és DTO-k közötti megfeleltetés, nézzük is meg, hogyan történhet mindez reaktív módon:
public class EmployeeService {
private final EmployeeRepository employeeRepository;
public Flux<EmployeeDto> listEmployees() {
return employeeRepository.findAll().map(this::toEmployeeDto);
}
public Mono<EmployeeDto> createEmployee(@RequestBody Mono<CreateEmployeeCommand> command) {
return command
.map(this::toEmployee)
.flatMap(employeeRepository::save)
.map(this::toEmployeeDto);
}
private EmployeeDto toEmployeeDto(Employee employee) {
return new EmployeeDto(employee.getId(), employee.getName());
}
private Employee toEmployee(CreateEmployeeCommand command) {
return new Employee(command.getName());
}
}
Integráció
Természetesen ha külső rendszer REST webszolgáltatását akarjuk meghívni, akkor is aszinkron nem-blokkoló módon kell megtennünk.
Erre biztosítja a Spring a org.springframework.web.reactive.function.client.WebClient osztályt.
Ha a reaktív gondolkodásmódba jobban beépülő kommunikációs formát akarunk választani, akkor használható az RSocket bináris protokoll, vagy használhatunk valamilyen üzenetküldő megoldást, pl. RabbitMQ-t, vagy Kafkát.
A témáról workshopot is tartottam a III. Országos IT Megmérettetés Díjátadó rendezvényén (YouTube videó), melynek a Training360 is kiemelt támogatója. A slide-ok itt is elérhetőek.
Az ahhoz tartozó példaprojekt megtekinthető a GitHub-on. Ez egy háromrétegű alkalmazás, Spring WebFlux-szal, Spring Data R2DBC-vel, H2 adatbázissal. Sőt WebClienttel egy http kérést is küldd egy külső alkalmazás felé.