Fa ábrázolása adatbázisban
Frissítve: 2026. március 26.
Gyakran megesik, hogy adott egy probléma, melyet már megoldottam az általam használt eszközökkel, de egy kicsit jobban körülnézve olyan alternatív megoldásokat találok, melyekről nem is hallottam, sőt a környezetemben sem ismert, mégis egyszerű, jól használható, csak nem annyira elterjedt.
Ilyenbe futottam, mikor Javaban egy fát akartam kezelni, és relációs adatbázisban eltárolni. A leggyakoribb ábrázolási forma az Adjacency list, azaz szomszédsági lista, ekkor a gyermekek vannak eltárolva egy listában. Ezt relációs adatbázisban úgy képezhető le, hogy minden csúcs tartalmaz egy külső kulcsot a szülő csúcsra. A probléma akkor van, mikor egy részfát szeretnék lekérdezni. Itt ugye a táblát magával kell joinolni, de előre nem tudom, hogy hányszor, milyen mélységű a részfa. Itt be kell járnom a fát, és a gyermekeket minden csúcshoz külön lekérdezésben lekérdezni.
A hierarchikus adatok kezelésére bizonyos adatbázisok beépített
megoldásokat tartalmaznak, pl. Oracle esetén a START WITH és CONNECT BY
parancs, vagy esetleg tárolt eljárásban is megvalósíthatjuk a hierarchia
elemeinek összegyűjtését. Ezek használatakor azonban
bukjuk a platformfüggetlenséget.
Van viszont egy másik ábrázolási forma, a Nested set model.
A poszthoz tartozó példaprogram elérhető a GitHubon.
Nézzük először az Adjacency list ábrázolást JPA-val.
Definiáltam egy Node osztályt, mely egy csúcsot reprezentál.
Ennek van egy parent nevű, Node típusú attribútuma, mely egy referencia a
szülő csúcsra, és van egy children nevű, List<Node> típusú attribútuma, mely a
gyermek csúcsokra mutató referenciákat tartalmazza. A következő
forráskód mutatja a Node osztály vázát.
@Entity
public class Node {
// ...
@ManyToOne
private Node parent;
@OneToMany(mappedBy="parent", cascade = CascadeType.REMOVE)
private List children = new ArrayList();
// ...
}
Az első probléma akkor adódik, ha a gyermekek sorrendje nem mindegy.
Ugyanis a JPA alapban nem veszi figyelembe, hogy a List-ben számít a
sorrend. Amennyiben egy új gyermeket veszek fel már létező gyermekek
mellé, a következő lekérdezésnél nem garantált az, hogy ugyanazon
sorrendbe kapom vissza a gyermekeket, ahogy a List-ben szerepeltek. Ez
abból adódik, hogy az adatbázis rekordok között nincs sorrend
definiálva, így általában olyan sorrendben kapom vissza az rekordokat,
ahogy az adatbázisba kerültek (de erre sem szabad építeni, mert
különböző műveletek, optimalizációk miatt más sorrend is lehetséges).
Ehhez használhatjuk a JPA @OrderColumn annotációját, melyet a JPA automatikusan
karbantart. Nézzük
tehát a módosított Node osztályunkat:
@Entity
public class Node{
// ...
@ManyToOne
private Node parent;
@OneToMany(mappedBy="parent", cascade = CascadeType.REMOVE)
@OrderColumn(name = "index")
private List children = new ArrayList();
// ...
}
A következő probléma akkor adódik, mikor egy teljes részfát kell
megjeleníteni. Amennyiben egy listába be akarjuk tenni a részfa összes
elemét (pl. grafikusan meg akarjuk jeleníteni és listában kívánjuk
átadni a megjelenítési rétegnek), a részfát preorder módon, rekurzívan
be kell járnunk. Ekkor viszont minden egyes Node esetén a gyermekek
lekérdezésekor, amennyiben lazy fetch type-ot alkalmaztunk (és
@OneToMany kapcsolat esetén ez az alapértelmezett), minden esetben lefut
egy query, mely lekérdezi a gyermek Node-okat. Akkor sem jobb a helyzet,
ha eager fetch type-ot alkalmazunk, mert ekkor nem a bejáráskor, hanem
már a betöltéskor fog lefutni az összes query, azaz pontosan annyi,
amennyi csúcsból áll az adott részfánk.
A háttérben a Node osztály egy NODE táblára képződik le, melynek van egy
PARENT_ID külső kulcsa, és a gyermekek lekérdezése esetén egy olyan
selectet futtat, mely lekérdezi az összes olyan NODE sort, melynek
PARENT_ID oszlopa megegyezik a szülő azonosítójával
(SELECT * FROM node WHERE parent_id = ? ORDER BY rank ASC).
Viszont van egy ennél sokkal hatékonyabb hierarchikus adatszerkezet reprezentáció, melyet nested set modelnek hívnak. Ez ugyan lekérdezéskor gyors, de módosításkor a több művelet miatt lassabb, így csak akkor érdemes használni, ha sok a lekérdezés, és viszonylag kevés a módosítás.
A megértéshez nézzünk is egy példa fát. A trükk, hogy minden egyes
Node-hoz felveszünk egy bal és egy jobb értéket. Egy létező fa esetén
ezeket a számokat úgy osztjuk ki, hogy a gyökér csúcs bal értéke lesz az
1, és megyünk végig gyermekeken mélységi kereséssel, és a bal értékhez
mindig hozzáadunk egyet. Ha levélelemhez érünk, akkor folytatjuk a
számolást visszafele, a szülő fele, és kitöltjük a jobb értékeket, míg
egy testvérhez érünk, és ekkor ismét a bal értékeket osztjuk ki, és így
tovább. Gyakorlatilag óramutató járásával ellentétes irányban
körbejárjuk a fát.
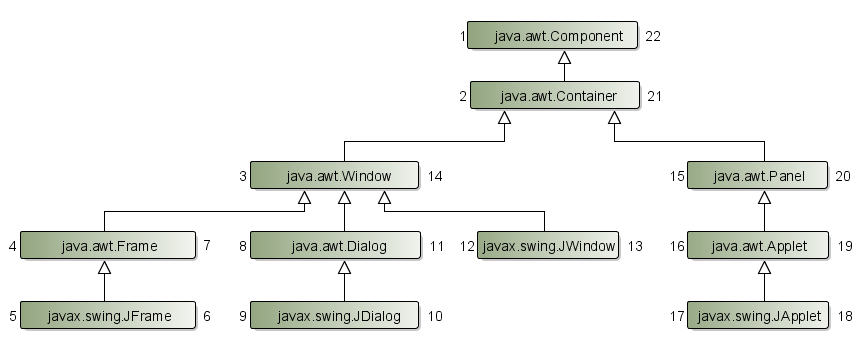
Az így nyert számozás azért nagyon hatékony részfák lekérdezésére, mert egy elem részfáját úgy kérhetjük le, ráadásul a preorder bejárással adott sorrendnek megfelelően, hogy lekérdezzük azon elemeket, melyek bal értéke a szülő bal értékénél nagyobbak és a jobb értékénél kisebbek, a bal érték alapján rendezve. Így a teljes részfa egy lekérdezéssel előállítható, szemben a rekurzív módszerrel, ahol annyi lekérdezésre volt szükség, ahány elemből állt a fa. Ez a sorrend tökéletes a fák ábrázolására, pl. egy menü vagy egy oldaltérkép megjelenítésére.
A számozás alapján látható, hogy egy elem összes leszármazottjának a
számát is könnyen megkaphatjuk: (bal érték - jobb érték - 1) / 2. Ez
akkor lehet különösen hasznos, ha ezt a felületen is meg szeretnénk
jeleníteni.
Szintén könnyen észrevehető összefüggés, hogy a levélelemekre igaz az az
állítás, hogy jobb érték - bal érték = 1.
Az egyszerűség kedvéért hagyjuk meg a szülőre mutató referenciát,
valamint javasolt egy attribútum felvétele, mely megadja az adott elem
mélységét a fában (level). Mindkettőt persze ki lehet számolni
lekérdezésekkel is. De ezen attribútumok használatával egyszerűbbek
lesznek a lekérdező műveleteink, de több helyet foglal, és módosításkor
többet kell adminisztrálni. A bal értékek már definiálják a sorrendet. Így
néz ki tehát az osztályunk:
public class Node {
// ...
private int left;
private int right;
private int level;
@ManyToOne(fetch=FetchType.LAZY)
private Node parent;
// ...
}
Egy adott elem és annak leszármazottainak lekérdezése tehát a következő JPA lekérdezéssel adható meg, ahol az első paraméter a kiválasztott elem bal értéke, a második paraméter a kiválasztott elem jobb értéke:
SELECT node FROM Node node WHERE node.left BETWEEN :first AND :last ORDER BY node.left
Tehát ha pl. a java.awt.Window elemet és annak összes leszármazottját
akarjuk lekérdezni, akkor az összes elemet kell lekérdezni, melynek a
bal értéke nagyobb, mint 3, és a jobb értéke kisebb, mint 14, a bal
érték szerint rendezve.
Igaz, hogy a lekérdezés nagyon egyszerű, de a beszúrás viszont bonyolultabb. Amennyiben ugyanis egy elemet akarunk beszúrni, először ki kell választani a beszúrás helyét. Ha a beszúrandó elem
- a kiválaszott elem első gyermeke lesz, az új elem bal értéke a kiválasztott elem bal értéke + 1 lesz
- a kiválaszott elem utolsó gyermeke lesz, az új elem bal értéke a kiválasztott elem jobb értéke lesz
- a kiválaszott elem bal testvére lesz, az új elem bal értéke a kiválasztott elem bal értéke lesz
- a kiválaszott elem jobb testvére lesz, az új elem bal értéke a kiválasztott elem jobb értéke + 1 lesz
Az új elem jobb értéke, mivel az elemnek még nincs gyermeke, az új elem bal értéke + 1 lesz. Ez után egy “eltoltást” kell elvégezni, ugyanis lehetséges, hogy az így kiosztott számok már foglaltak. Ehhez két művelet szükséges, egyrészt az összes olyan elem bal értékéhez, melynek a bal értéke nagyobb, vagy egyenlő, mint a beszúrandó elem bal értéke, hozzá kell adni 2-t. Valamint az összes olyan elem jobb értékéhez, melynek a jobb értéke nagyobb, vagy egyenlő, mint a beszúrandó elem bal értéke, hozzá kell adni 2-t. Ez két egyszerű JPA bulk update művelettel is elvégezhető, ahol a paraméter a beillesztendő elem bal értéke:
UPDATE Node node SET node.left = node.left + 2 WHERE node.left >= :position
UPDATE Node node SET node.right = node.right + 2 WHERE node.right >= :position
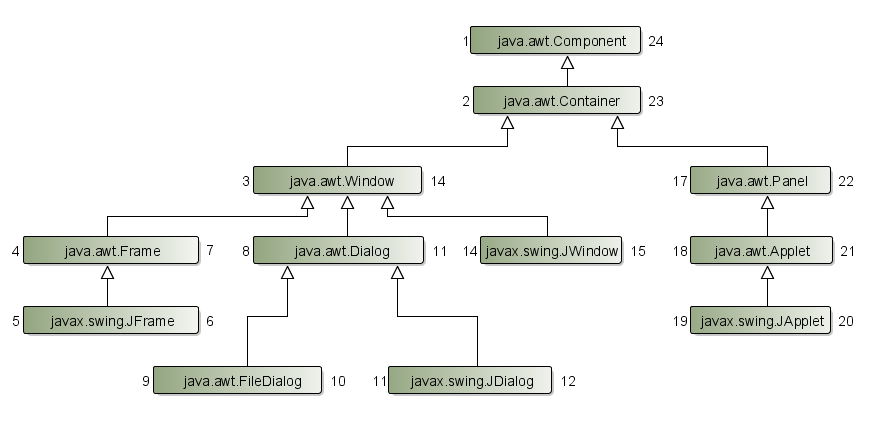
Vegyük példaként, hogy a java.awt.Dialog elem első gyermekeként egy
java.awt.FileDialog elemet akarunk felvenni. Az új elem bal értéke 9
lesz és a jobb értéke 10. Majd az összes elem bal értékét 2-vel növelni
kell, melynek bal értéke nagyobb vagy egyenlő, mint 9, és ugyanígy az
összes elem jobb értékét 2-vel növelni kell, melynek jobb értéke nagyobb
vagy egyenlő, mint 9.
Ezek alapján a további műveletek is könnyen implementálhatóak. Egy részfa törlésénél töröljük az adott elemet, majd az így keletkezett “lyukra” húzzuk vissza a mögötte elhelyezkedő elemeket. Mivel nem csak egy elemet, hanem teljes részfát is törölhetünk, az eltolás nem 2-vel történik, hanem a részfa elemszáméval, melynek kiszámolását már fentebb leírtam.
A gyökértől adott elemhez vezető utat is egy lekérdezéssel megkaphatjuk, ugyanis a felmenő elemek mindegyikére igaz, hogy bal értékük kisebb, mint a kiválasztott elem bal értéke, és a jobb értékük viszont nagyobb, mint a kiválaszott elem jobb értéke. Ezt tehát a következő JPA lekérdezéssel kapjuk meg, ahol az első paraméter a kiválasztott elem jobb, a második a bal értéke:
SELECT node FROM Node node WHERE node.left < :left AND node.right > :right ORDER BY node.left
Az elem közvetlen gyermekeinek, valamint egy elem testvéreinek lekérdezése a parent mutató miatt nagyon egyszerű.
A legbonyolultabb persze a részfa mozgatása. Itt először vizsgálni kell, hogy nem-e önmagába akarjuk-e mozgatni. Utána a következő lépéseket kell elvégezni:
- Először ki kell számolni a részfa szélesességét (a bal és jobb érték közötti különbséget)
- Majd ideiglenesen kivágjuk a részfát, a negatív tartományba való eltolással
- Bezárjuk a lyukat, a későbbi elemek előre tolásával
- Meg kell határozni az új pozíciót
- Majd helyet kell csinálni a részfának az új pozíció után történő elemek hátra tolásával
- Majd visszahozzuk a részfát a negatív tartományból, és áttoljuk az új pozícióra
Ebből látszik, hogy ez a megoldás sem egyértelműen jobb, mint a klasszikus mutatós megoldás, de akkor jobban használható, ha sokkal több a lekérdezés, mint a módosítás. Az elemnek létrehoztam egy közös interfészt, melynek egyik implementációja mutatókat tartalmaz, másik leszármazottja pedig a bal és jobb értékeket. A műveletekhez definiáltam egy absztrakt ősosztályt, és két leszármazottját, mindkettő Spring service.
A tesztesetek is nagyon érdekesek. Hiszen egy interfész két implementációját kell ugyanazokkal a
tesztekkel meghajtani. Ehhez létrehoztam egy absztrakt ősosztályt, és két leszármazottját.
Az ős definiálja a getNodesService() metódust, melyet a leszármazottak úgy valósítanak meg,
hogy injektálják típus alapján a megfelelő service-t, és azt adják vissza a metódusok.
A témáról egy magyar cikk is megjelent PHP megvalósítással. A poszt írásakor ez a Java kódrészlet is nagyon hasznos volt, mely egyszerű JDBC-t használ.