Clusterezés általában és Tomcaten
A skálázatóság (Scalability) és magas rendelkezésre állás (High availability) fogalma ugyan gyakran használatos, mégis alapvető félreértések szoktak ezzel kapcsolatban adódni. A skálázhatóság azt jelenti, hogy újabb erőforrások hozzáadásával (gondoljunk hardver hozzáadására), nő a rendszer áteresztőképessége. Azaz nagyobb terhelés esetén több felhasználót/gyorsabban tud kiszolgálni. A skálázhatóságnak két formája van. A vertikális skálázhatóság (skale up) során ugyanabba a szerverbe több processzort, memóriát téve nő annak áteresztőképessége. Horizontális skálázhatóság esetén több szervert állítunk be, melyek kiszolgálják a felhasználói kéréseket. A magas rendelkezésre állás biztosítása esetén olyan tervezést, implementációt, olyan eszközöket és technológiákat választunk, melyek használatával egy adott időintervallumon belül csökkentjük a leállási idő (downtime) hosszát, amikor is a felhasználó nem fér hozzá a rendszerhez. A magas rendelkezésre állású rendszerek fejlesztése különösen fontos kórházakban, bankokban, repülőtereken és TELCO cégeknél. A leállás lehet előre tervezett (planned), mint pl. tipikusan éjszakai telepítés, vagy véletlenszerű is, amit valamilyen hiba okozhat. A magas rendelkezésreállást százalékban szokták megadni. Gyakran lehet hallani az “öt kilences” rendelkezésreállású rendszert, mely azt jelenti, hogy egy évben az idő 99,999%-ában működik, azaz 0,001%-ban áll. Ez 365*8*60 * 0,001 / 100 = 5,256 perc. Gyakori félreértés, hogy a rendszer (az üzemeltetés szerint) működött, csak épp a felhasználó nem tudta használni (pl. ment a hardver, szoftver, csak éppen hálózati kapcsolat nem volt). Természetesen ez leállásnak minősül. Azzal is szoktak itt trükközni, hogy mi is a teljes leállás. Ha a felhasználó elér bizonyos funkciókat, csak éppen a dolgát nem tudja elvégezni, az leállásnak minősül-e? Persze ezt már nem olyan könnyű definiálni. Szorosan ide tartozik a visszaállás ideje is (recovery time), mely azt adja meg, hogy bizonyos események esetén mennyi idő alatt lehet visszaállni (pl. mentésből). Itt is figyelembe kell venni, hogy pl. egy szoftveres hiba esetén pl. elegendő lehet egy virtuális gép visszamásolása és elindítása, adatvesztés esetén már valamilyen adathordozóról kell visszaállítani az adatokat, de egy árvíz esetén, ahol úsznak a szerverek, már több időre van szükség (ha nincs pl. másodlagos, helyilag szeparált másolat). Az SLA (service level agreement) írja le a magas rendelkezésre állási célokat és követelményeket. Amerikából jövő hírekben lehet hallani, hogy egy fél napos leállás hány millió dolláros károkat tud okozni, de hazai példa is van, mikor a T-Mobile hálózata fél napra szoftverfrissítés következtében felmondta a szolgálatot.
Nézzük még az ide kapcsolódó fogalmakat. A hibatűrés (fault tolerance) annak a foka, hogy a rendszer mennyire képes elviselni egy-egy komponensének hibáját, mennyire lesz ez észrevehető a felhasználó számára. Single point of failure-nek nevezzük azt a komponenst, mely kiesése esetén a rendszer megáll. Ezen pontok kiküszöbölésére a megoldás, hogy a komponensből több példányt állítunk be. Sajnos ennek nem csak előnyei vannak, hanem hátrányai is. Több komponens bevezetésével ugyanis bonyolódik az architektúránk, több komponens hibásodhat meg, és sokkal nehezebb lesz a hibakeresés, magasabb a telepítési és üzemeltetési költség, képzettebb szakemberekre van szükség. Amennyiben több komponenst állítunk be ugyanannak a feladatnak az elvégzésére (redundancia), melyek a kliensei számára transzparensek, fürtözésről (cluster) beszélünk, mely a horizontális skálázhatóság eszköze. A fürtözés esetén lehetőség van magas rendelkezésre állású fürtök kialakításásra (High-availability (HA) clusters), melyek kialakításánál alapvető cél, hogyha valamelyik komponens meghibásodás folytán kiesik, helyét egy másik komponens vegye át (failover). Beszélhetünk aktív/aktív (active/active) fürtről, mikor két komponens esetén mind a kettő kiszolgálja a kéréseket, valamint beszélhetünk aktív/passzív (active/passive) fürtről, mikor csak az egyik komponens működik, a másik nem szolgál ki felhasználókat. A passzív tag lehet működő/bekapcsolt, mely nem szolgál ki kéréseket, viszont gyorsan üzembe állítható (hot), és lehet kikapcsolt állapotban is, mely nem pazarol energiát, de elindítása időbe telik (cold). A fürt tagjai ún. heartbeat (szívverés) segítségével jelzik, hogy még működésben vannak. Amikor a szívverést a másik fél nem érzékeli, de ettől független mindkét komponens funkcionál (pl. a köztük lévő hálózati kapcsolat szakad meg), “split-brain” effektus léphet fel, mikor mind a kettő azt hiszi magáról, hogy él, és a másik halott. Ez hamar inkonzisztens működéshez és adatokhoz vezethet.
Beszélhetünk ezen kívül terheléselosztásról is (load-balancing clusters), ekkor amikor kérés jön be a felhasználó felől, valamilyen szabály alapján dönteni kell, hogy melyik komponenshez továbbítódik a kérés. Ezt egy terheléselosztó végzi. Itt felmerül a kérés, hogy mi van akkor, ha a terheléselosztó hibásodik meg? Ekkor azt is clusterezzük? Mindig lesz a rendszerben egy single point of failure. A terhelés elosztás esetén, amennyiben a komponenseink állapot tartóak, azaz egy állapot megmarad két felhasználói kérés között (felhasználói munkamenet, session), mit lehet tenni? Az egyik válasz, hogy az állapotot egy olyan helyen tároljuk, mely közös, és melyhez mind a két komponens hozzáfér. Ez lehet egy adatbázis, elosztott cache, stb. Másik megoldás lehet, hogy a felhasználó kéréseiről gondoskodunk, hogy mindig ugyanahhoz a komponenshez essenek be, ennek neve session affinity, vagy sticky session. Vagy választhatjuk azt is, hogy mindegy melyik komponenshez esik be a kérés, a komponensek között megoldjuk az állapotok replikálását (session replication). Ez esetben is érdemes lehet bekapcsolni a sticky sessiont. Ebből látszik, hogy legegyszerűbb dolgunk akkor van, ha nem állapottartó a rendszerünk.
De mi alapján döntsön a terheléselosztó, hogy hova ossza kérést? A legegyszerűbb megoldás, hogy körben forgó (round robin) DNS-t használunk, és így hálózati szintre toltuk le a megoldást, azaz a felhasználó kérésében szereplő domain nevet a dns hol az egyik, hol a másik ip-címre fogja feloldani. Történhet véletlenszerűn, egyszerűbb algoritmusok alapján (pl. minden páros ip-címről érkező kérés az első komponensre megy), vagy egész bonyolult algoritmusok alapján. Bizonyos terhelészelosztók tudják azt, hogy figyelik a komponenseket, és amennyiben az egyik leáll, annak nem osztanak további kéréseket (health checking). Lehetőség lehet ún. graceful shutdownra is, amikor tervezett leállás, pl. új verzió kirakása esetén először kiiktatjuk az egyik komponenst. A terheléselosztó új kéréseket erre már nem irányít, de a már folyamatban lévő kéréseket, felhasználói munkameneteket kiszolgálja, gyakorlatilag megvárja, hogy a kérések kifussanak. Ha az összes kérés megszűnt, el lehet végezni rajta a karbantartást, és újra visszakapcsolni, hogy fogadhasson kéréseket. Majd ugyanezt kell eljátszani a másik komponenssel is. Ezáltal megoldható a leállás nélküli telepítés/karbantartás. Bizonyos terheléselosztók tudják azt is, hogy figyelik a háttér komponensek terhelését, és a kérést annak oszthatják, melyek terhelése a legalacsonyabb. Alkalmazás clusterezése estén úgy is elvégezhetjük a különböző komponensekre való szétosztást, hogy minden komponensre ugyanazt a konfigurációt tesszük, tehát gyakorlatilag szimmetrikusak, ugyanazokat a szolgáltatásokat biztosítják. De funkciónként szét is választhatjuk azokat, pl. külön szerverekre helyezzük el a különböző alkalmazás rétegeket, pl. üzleti logikát és felhasználói felületet szétválasztjuk, vagy pl. az erőforrásigényes műveleteket külön szerverekre, akár céleszközökre bízzuk, mint pl. thumbnail generálás, riport generálás, PDF előállítás, XML feldolgozás, stb.
Látható, hogy a témakör korántsem egyszerű, és nincs egységes megoldás. Mindegyiknek van előnye és hátránya is. Cél, hogy a megrendelői igényeket nem funkcionális követelményekként gyűjtsük össze, és ez alapján válasszunk olyan megoldást, mely költség/érték arányban a legmegfelelőbb.
Végtelen lehetőség közül választhatunk, mind architekúrálisan, mind eszközileg. Vannak hardveres/szoftveres megoldások, kereskedelmi és fizetős termékek.
Ebben a posztban a Tomcat terheléselosztásáról és a Tomcat fürtözéséről fogok írni. A konfigurációt Windowson mutatom be, de könnyen adoptálható Linuxra is. Az aktuális verziók: Apache HTTP Server 2.2.15, Apache Tomcat 6.0.26. A témában magasan a legjobb könyv a Professional Apache Tomcat 6 (WROX Professional Guides)

A legegyszerűbb konfiguráció, ha a felhasználók kéréseit a Tomcat szolgálja ki egy példányban. Ennél bonyolultabb konfiguráció, ha a Tomcat elé egy web szervert, tipikusan egy Apache HTTP Servert tesztünk. Ez sok helyen maradvány, ugyanis a statikus tartalmat régebben a C-ben implementált HTTP Server sokkal gyorsabban szolgált ki. Ma már ez nem szempont, a Tomcat is képes ugyanolyan sebesség elérésére. HTTP Servert persze most is választhatunk, ha olyan funkciókra van szükségünk, melyek ezekben implementáltak, valamint ehhez értünk. A HTTP Server elterjedtsége miatt nagyon sokan dolgoznak azon, hogy biztonságos web szerver legyen, de pont ezen elterjedtsége miatt a támadások elsődleges célpontja is. Abban az esetben viszont, ha több Tomcat példányunk van, melyek között a terhelést el kell osztani, nem sok választásunk van, valamilyen terheléselosztót alkalmazni kell. Ez lehet a már említett round robin DNS, hardveres céleszköz, a tűzfalaknak is vannak ilyen megoldásaik, Linuxos megoldások (Pound, HAProxy), vagy választhatjuk az Apache HTTP Servert. A következőkben az Apache HTTP Server konfigurálását fogom bemutatni.
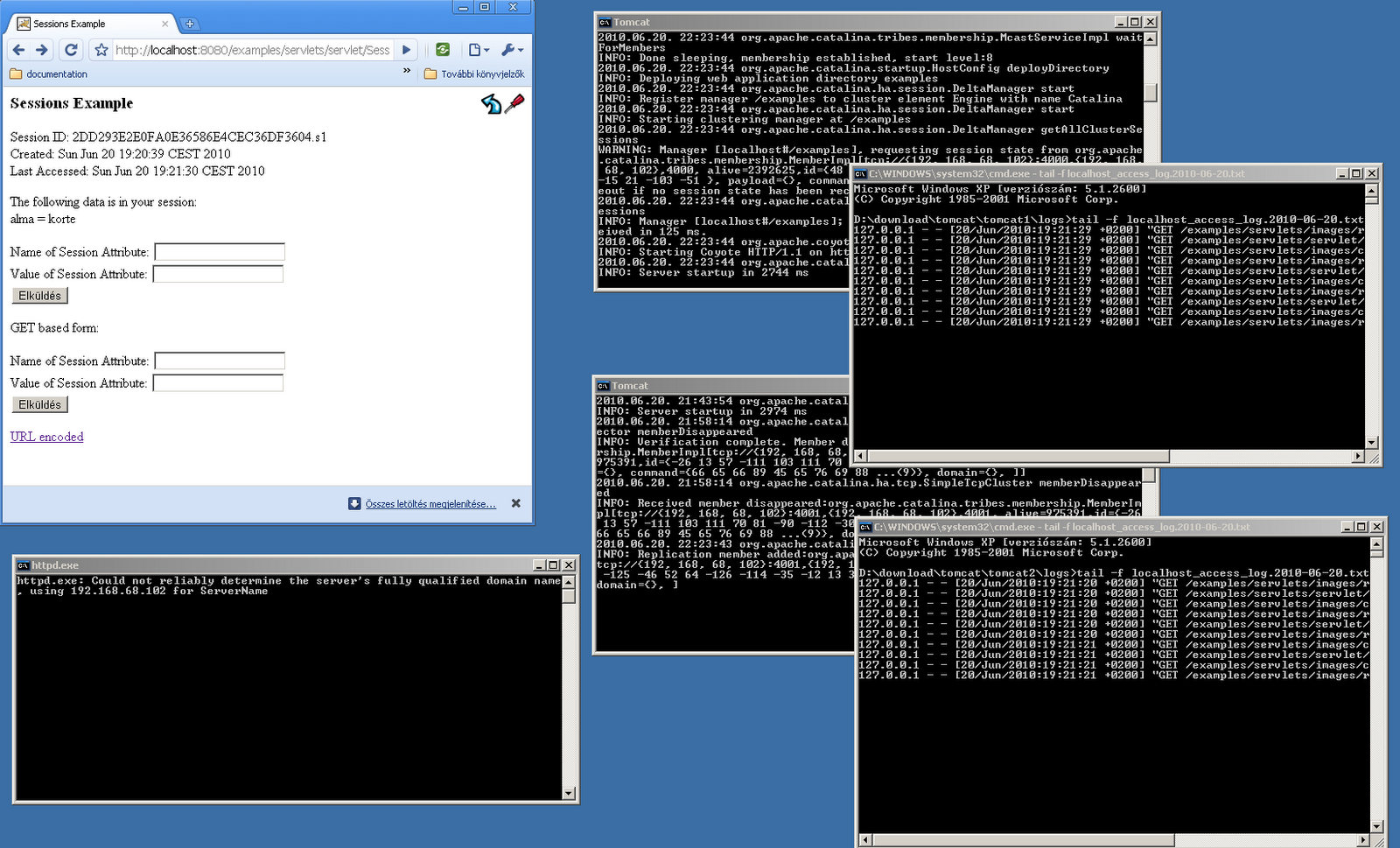
Több Tomcat példány indítása
Lehetőségünk van egy számítógépen is több Tomcat példányt indítani úgy, hogy csak egy binárist használjon. Ehhez egyrészt telepítsük fel a Tomcatet (pl. C:\Kaffe\apache-tomcat-6.0.26), erre a CATALINA_HOME környezeti változóval lehet majd hivatkozni, majd mindegyik példánynak hozzunk létre egy külön könyvtárat (pl. C:\Kaffe\tomcat1, C:\Kaffe\tomcat2), erre a CATALINA_BASE környezeti változóval lehet hivatkozni. A következő lépéseket mindkét példányon csináljuk meg, a CATALINA_BASE alatt. Hozzunk létre egy bin, conf és webapps könyvtárat. A bin könyvtárban hozzunk létre egy startup.bat állományt, a következő tartalommal:
SET CATALINA_HOME=C:\Kaffe\apache-tomcat-6.0.26
SET CATALINA_BASE=C:\Kaffe\tomcat1
%CATALINA_HOME%\bin\startup.bat
Természetesen a második példánynál a CATALINA_BASE értéke C:\Kaffe\tomcat2 legyen. Ez jelzi az indító scriptnek, hogy a bináris a apache-tomcat-6.0.26 könyvtárban, de a példány konfigurációja a tomcat1 és tomcat2 könyvtárban helyezkedik el. A conf könyvtárba másoljuk át a CATALINA_HOME/conf könyvtár tartalmát, és szerkesszük meg a server.xml állományt. Egyrészt mindkét példánynál kommentezzük ki az AJP connectort (<Connector port=”8009” …), hiszen kizárólag HTTP connectort fogunk konfigurálni. Az első példány server.xml-jében állítsuk a HTTP connector portot 8080-ról 8081-re, majd a második példány server.xml-jében állítsuk át a szerver portot 8005-ről 9005-re, és a HTTP connector portot 8080-ról 9080-ra. Így elkerülhetjük, hogy a különböző példányok port ütközésbe kerüljenek. Javasolt még az AccessLogValve-t bekapcsolni, azaz kivenni megjegyzésből, mert így nyomon követhetjük a kéréseket, hogy melyik példány szolgálta ki a felhasználót. A webapps könyvtárba másoljuk át a bináris examples könyvtárát, ugyanis ebben szerepel egy példa a session kezelésre, amivel tesztelhetjük majd a terheléselosztást, és fürtözést.
Terheléselosztás Apache HTTP Serverrel
Az Apache HTTP Server több moduljával is megoldhatjuk a feladatot. Mark Thomas: Deciding between mod_jk, mod_proxy_http and mod_proxy_ajp cikke alapján választhatunk a mod_jk, mod_proxy_http és mod_proxy_ajp között. A mod_proxy_ajp-vel elég sok problémája akadt, így azt nem javasolja. Helyette a mod_jk és mod_proxy_http között választhatunk. Mindkettő C/C++-ban implementált, az Apache HTTP Serverbe beépülő modul. Ha szabadon választhatunk, akkor inkább a mod_proxy_http ajánlott, mivel az az összes többi HTTP Server modulhoz hasonlóan konfigurálható, szemben a mod_jk-val ahol egy workers.properties állományt kell létrehoznunk. Amennyiben már használjuk az egyiket, és meg vagyunk vele elégedve, nem érdemes átállni a másikra. Ha a HTTP Server és a Tomcat közöt a kommunikációt titkosítani akarjuk, javasolt a mod_proxy_http alkalmazása, mert annak konfigurációja könnyebb. Ha az SSL-t a HTTP Server végződteti, de az SSL információkat a Tomcatnek tovább akarjuk passzolni, akkor javasolt a mod_jk. A Load Balancer HOW-TO is ezt a két megoldást említi. Vannak a neten még hivatkozások régebbi megoldásokra, azok már nem támogatottak.
Ezek miatt a mod_proxy_http konfigurálását fogom bemutatni.
A HTTP Server és a Tomcat között a HTTP és az AJP protokollt is választhatjuk. Az AJP (Apache JServ Protocol) egy csomag-alapú, bináris protokoll a TCP/IP felett, így hatékonyabb, mint a szöveges HTTP protokoll. Előnye, hogy képes a HTTP Server és a Tomcat közötti kapcsolatokat újra felhasználni, így nem kell minden kérésnél kiépíteni a TCP/IP kapcsolatot, csökkentve ezzel a latency-t. Mind a mod_jk, mind a mod_proxy képes AJP-n kommunikálni, aminak a másik oldala a Tomcat oldalon a Javaban implementált AJP Connector.
A mod_proxy_http konfigurálásához telepítsük fel az Apache HTTP Servert, majd a httpd.conf konfigurációs állományt szerkesszük meg. A moduloknál kapcsoljuk be a mod_proxy.so, mod_proxy_http.so és a mod_proxy_balancer.so modulokat. A terheléselosztához konfiguráljuk a következőket:
<Location /balancer-manager>
SetHandler balancer-manager
</Location>
ProxyRequests Off
ProxyPreserveHost On
ProxyPass /examples balancer://cluster/examples
ProxyPassReverse /examples balancer://cluster/examples
<Proxy balancer://cluster>
BalancerMember http://localhost:8081
BalancerMember http://localhost:9081
</Proxy>
A balancer-manager szekció lehetővé teszi, hogy a böngészőbe a /balancer-manager címet beírva egy táblázatot kapunk a cluster tagok állapotáról.
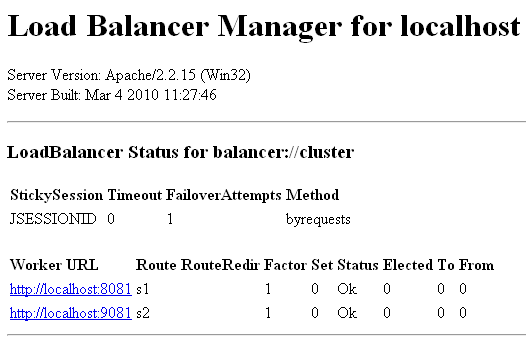
A ProxyRequests direktíva kikapcsolja a proxy-zást, kivéve a ProxyPass és ProxyPassReverse sorokban megadottaknál. A ProxyPreserveHost direktíva bekapcsolja, hogy a kért host információit továbbadja a mod_proxy_http. A ProxyPass direktíva megmondja, hogy a /examples címre érkező kéréseket a balancerre irányítsa, melyet később konfigurálunk. A ProxyPassReverse lehetővé teszi az Apache-nak, hogy a HTTP válasz fejlécében a Location, Content-Location és URI értékeket átírja. Erre akkor lehet szükség, hogyha redirect van, és az alkalmazás nem tudja a szerver címét, melyen meg lett szólítva. Ilyenkor a HTTP Server írja át a megfelelőre. Ha ekkor meghívunk többször egymás után egy URL-t (/examples/servlets/servlet/SessionExample), láthatjuk, hogy a kérések mindkét Tomcat példányra beesnek. Az alapértelmezett elosztás a byrequests, kérésenként ide-oda oszt, de a ProxySet lbmethod=bytraffic direktívával mindig annak oszt, aki a legkevesebb adatot forgalmazta (súlyozva), a bybusyness esetén pedig a szerint, hogy éppen hol van a legkevesebb aktív kérés (szintén súlyozható).
A webes alkalmazásoknál a session kezelés nem magától érthetődő, mivel a HTTP szabvány állapotmentes, hanem általában cookie alapú. Ilyenkor a felhasználó böngészője felveszi a kapcsolatot a Tomcattel, míg az kiállít egy session azonosítót, és cookie-ban visszaküldi a böngészőnek (JSESSIONID néven), valamint a memóriában tárolja a felhasználóval kapcsolatos adatokat. A munkamenet során a böngésző minden esetben elküldi a Tomcatnek a session azonosítót, mely alapján előveszi a memóriából a felhasználóhoz tartozó adatokat. Amennyiben a cookie ki van kapcsolva a böngészőben, történhet úgy is, hogy a session id mindig URL paraméterként megy át. (Itt tetszett az egyik könyvben szereplő hasonlat, mikor a ruhatárban leadjuk a kabátunkat, kapunk egy bilétát. A nehéz kabát a ruhatárba marad, és mi csak a bilétát visszük magunkkal.) Ráadásul figyelnünk kell arra is, hogy a cookie domain névhez kötött, azaz ha egy jólirányzott redirecttel egy másik domainre irányítjuk át a felhasználót, amin ugyan elérhető az alkalmazás, a sessionje el fog veszni, mert a böngésző az új domainre nem fogja küldeni a cookie-t.
Amennyiben sticky sessiont is akarunk konfigurálni, két dolgot kell tennünk. Első körben be kell állítanunk a Tomcatben, hogy a session azonosítójába tegye bele a megfelelő példány azonosítóját. Ehhez a server.xml-ben az Engine tag jvmRoute attribútumába állítsuk be az első példányon a jvmRoute=”s1”, a második példányon a jvmRoute=”s2” értéket. Ekkor ha közvetlenül szólítjuk a Tomcatet, láthatjuk, hogy a session azonosító postfix-e .s1 vagy .s2 lesz (pl. Session ID: 24ED67056B3213387399FE4DE4DBC3F0.s1). Következő lépésként a HTTP Server konfigurációjában kell beírnunk, hogy sticky sessiont alkalmazzon, és ehhez vegye figyelembe a JSESSIONID nevezetű header értéket, ahol az első példánynál az s1, második példánynál az s2 fog benne szerepelni.
ProxyRequests Off
ProxyPreserveHost On
ProxyPass /examples balancer://cluster/examples stickysession=JSESSIONID
ProxyPassReverse /examples balancer://cluster/examples
<Proxy balancer://cluster>
BalancerMember http://localhost:8081 route=s1
BalancerMember http://localhost:9081 route=s2
</Proxy>
Látható, hogy az előzőhöz képest a stickysession=JSESSIONID kulcs-érték, valamint a route=s1, és route=s2 kulcs-értékek változtak. Ez a konfiguráció mondja meg, hogyha a JSESSIONID kulccsal a fejlécben az érték s1-re végződik, akkor a hívást a http://localhost:8081 címre továbbítsa, s2 estén a http://localhost:9081 címre. Ekkor a példa program is helyesen fog működni, és megmaradnak a sessionbe tett értékek (/examples/servlets/servlet/SessionExample).
Session replikáció Tomcatben
A Tomcat a fürtözést a session replikációval támogatja. Ennek lényege, hogy a sessionbe tett adatok az összes többi futó példányban látszanak. A session replikációt különbözőképpen lehet megoldani. A Tomcat mentheti a session információkat közös fájlrendszerre, vagy mentheti adatbázisba, JDBC-n keresztül. Harmadik módszer lehet, hogy memóriában tárolhatja, és a a példányok a hálózaton egymás között átadják az adatokat. Ez utóbbiból is két megoldás van a Tomcatben. Vagy a sessionök az összes példány között replikálódnak, vagy kinevezünk elsődleges példányt, és egy backup példányt, és a session adatok csak a backup példányra replikálódnak.
A session replikációnak szintén vannak hátrányai. Egyrészt nehezebben konfigurálható, üzemeltethető. Perzisztens sessionök esetén megnő a tárhely igény, valamint az alkalmazás lassabb lehet, hiszen a perzisztálás időbe telik. Ugyanígy memóriában tartott session esetén megnőhet a kommunikáció a különböző példányok között, amihez elegendő sávszélesség szükséges. Ez utóbbi esetben ráadásul, mivel a sessionök nincsenek a tárba mentve, nem él túl egy teljes leállást, vagy rendszer újraindítást.
Amennyiben fürtözést akarunk konfigurálni, először győződjünk meg arról, hogy a példányok órája szinkronban van, javasolt NTP szolgáltatás használata is az idő szinkronizálására.
Az, hogy a Tomcateket fürtbe kötjük, még nem elegendő a session replikáláshoz, ehhez alkalmazásoként meg kell mondani, hogy clusterezhetőek, méghozzá a web.xml-ben fel kell venni a <distributable/> taget. Ekkor azonban az alkalmazás fejlesztésekor is be kell tartanunk néhány szabályt.
- A klasszikus Singleton többé nem singleton, hiszen JVM-enként van egy példányunk.
- Mindennek, amit sessionbe rakunk, implementálnia kell a java.io.Serializable interfészt.
- Tartsuk a sessionben tárolt elemek méretét alacsonyan, minimalizáljuk a példányok közötti kommunikációs forgalmat.
- Ha változtatjuk a sessionben tárolt értéket, mindig hívjuk meg a setAttribute metódust.
- A klasszikus párhuzamos porgramozással kapcsolatos műveletek, mint pl. a lockolás szintén csak JVM-en belül működnek.
- Lehetőleg ne használjunk fájlrendszert, ha mégis, akkor megosztott fájlrendszert, melyhez minden példány hozzáfér.
- Ütemezett feladatoknál figyeljünk, hogy nehogy mind a két példány elindítsa ugyanabban az időpontban. A legelterjedtebb ütemezési könyvtár, a Quartz ezt úgy oldja meg, hogy adatbázis lockokat használ.
- A sessionön kívül más nem replikálható.
Ahhoz, hogy ne okozzunk magunknak sok fejtörést, javasolt mind hardver, mind szoftver szinten teljesen egyforma példányokat, konfigurációkat alkalmazni. A következő részletet kell beilleszteni a server.xml-be az Engine tag alá.
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster">
<Manager className="org.apache.catalina.ha.session.DeltaManager"
expireSessionsOnShutdown="false"
notifyListenersOnReplication="true"/>
<Channel className="org.apache.catalina.tribes.group.GroupChannel">
<Membership
className="org.apache.catalina.tribes.membership.McastService"
address="239.255.0.3"
port="45564"
frequency="500"
dropTime="3000"/>
<Receiver
className="org.apache.catalina.tribes.transport.nio.NioReceiver"
address="192.168.10.10"
port="4000"
autoBind="0"
selectorTimeout="100"
maxThreads="6"/>
<Sender className="org.apache.catalina.tribes.transport.ReplicationTransmitter">
<Transport className="org.apache.catalina.tribes.transport.nio.PooledParallelSender"/>
</Sender>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.TcpFailureDetector"/>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.MessageDispatch15Interceptor"/>
</Channel>
<Valve className="org.apache.catalina.ha.tcp.ReplicationValve"
filter=".*\.gif;.*\.js;.*\.jpg;.*\.txt;"/>
<ClusterListener className="org.apache.catalina.ha.session.ClusterSessionListener"/>
</Cluster>Mindkét példánynál a Receiver tag address attribútumának értékét állítsuk a futtató gép ip-címére. Amennyiben ugyanazon a gépen futtatjuk a példányokat, a második példány esetén a Receiver tag port értékét állítsuk 4000-ről pl. 4001-re, ellenkező esetben a port ütközésre utaló hibaüzenetet kapunk (Caused by: java.net.BindException: Address already in use: bind).
A session replikációs fürtözés alapvetően az Apache Tribes keretrendszer használatával történik, melynek JAR állományai megtalálhatóak a Tomcat lib könyvtárában (catalina-ha.jar, catalina-tribes.jar). Az Apache Tribes ún. communication groupokat definiál, melyekbe a clusterben lévő példányok tartoznak. Ezek multicast ping üzenetekkel kommunikálnak egymással, a tagok heartbeat jelet küldenek, ezzel dinamikusan csatlakozni tudnak egy csoportba, vagy a heartbeat megszűnése esetén kikerülnek onnan. Ezért a hálózaton engedélyezni kell a multicastolást. Ezen kívül a Tribes biztos üzenettovábbítást is biztosít a tagoknak. A session átvitele már a példányok közötti pont-pont TCP/IP kapcsolaton keresztül történik.
A következőkben csak a fontosabb konfigurációkat írom le, a részletesebb elírás megtalálható a Clustering/Session Replication HOW-TO dokumentációban.
A Cluster tagen belüli className attribútum értéke jelenleg csak a SimpleTcpCluster lehet. A Manager tag megadása kötelező. Amennyiben a replikáció minden példánynak megy, a DeltaManager-t kell használni, amennyiben a példány csak a backup példányával replikál, használható a BackupManager. A notifyListenersOnReplication attribútum azt mondja meg, hogy replikáció esetén meg kell hívni a SessionListener implementációkat. A expireSessionsOnShutdown attribútum azt mondja meg, hogy le kell-e járatni a sessionöket és replikálni shutdownnál.
A Cluster tagen belül meg kell adni a Channel taget. Az Apache Tribes fogalma a csatorna, mely egy absztrakt hálózati végpont, hasonló a TCP/IP sockethez, melyen keresztül a csoport egy tagja tud üzenetet küldeni a csoportban lévő többi tagnak. Jelenleg a GroupChannel az egyetlen implementáció. A Membership tagen belül adható meg a csoporttagsággal kapcsolatos beállítások. Jelenleg csak a McastService implementáció adható meg. A address és port a multicast cím és port, melyen a tagok hallgatnak, az erre a címre küldött üzenetet az összes tag megkapja. A multicast cím 224.0.0.1 és 239.255.255.255 között bármennyi lehet, de a 224.* ésa 239.* címeket nem illik használni, mert a hálózat másra tarthatja fenn őket. A frequency adja meg ezredmásodpercben, hogy mennyi időközönként küldjön egy tag heartbeatet. A dropTime adja meg, hogy amennyiben egy tag ennyi ezredmásodpercig nem ad jelt magáról, a csoportból kizárásra kerül. A tagok a sessiont már pont-pont kapcsolaton viszik át. Ennek konfigurálására való a Receiver és Sender tag. A Receiver address és port attribútuma adja meg a címet és portot, amin egy tag fogadni fogja a session replikációs üzeneteket. Ha az autoBind 0, akkor implicit adunk meg a port tagben egy portot. Választható BioReceiver (blocking I/O), de nem ajánlott, csak azon régi JVM verzióknál, ahol a NIO-ban még sok bug volt. A selectorTimeout is egy régi bug kivédéséért van benne. A maxThreads adja meg, hogy hány szálon fogadja a session replikációs üzeneteket. Érdemes annyira állítani, amennyi tagból a cluster áll. A Sender tagben csak a ReplicationTransmitter javasolt, a Transport tagben a PooledMultiSender is választható, régebbi JVM-eknél javasolt.
Az Interceptor-ok láncolásával a channelhez további funkcionalitások adhatóak. Amennyiben nem érkezik heartbeat üzenet az egyik tagtól, a TcpFailureDetector megpróbálja felvenni vele a kapcsolatot, hogy megbizonyosodjon arról, hogy tényleg nem megy. A MessageDispatch15Interceptor asynchron message dispatcher, üzenetküldéskor aktiválódik. Van még a ThroughputInterceptor, mely INFO szinten képes naplózni a cluster üzeneteket. A Valve elemek ún. szűrők, melyek a clusterezésnél a hálózati forgalmat hivatottak csökkenteni azáltal, hogy bizonyos esetekben nem engedik tovább a session replikációt. Jelenleg csak a ReplicationValve használható, és a filter attribútumban lehet megadni, hogy milyen kéréseknél ne legyen replikáció. A példában pl. képeknél, szöveges és JavaScript állományok lekérésénél. A Cluster tagen belül megadhatjuk a Deployer taget is, mely egyszerűsíti a konfigurációt azáltal, hogy egy példányra deploy-olt war-t szétoszt a többi példány között. A dokumentáció szerint ezt élesben még ne alkalmazzuk, mert erősen fejlesztés alatt áll. DeltaManager használata esetén konfigurálni kell a ClusterSessionListener-t is, mely továbbítja az üzeneteket a DeltaManager-nek.
A session replikáció működése nyomon követhető, ugyanis naplóz, ha a logging.properties-ben a org.apache.catalina.tribes.MESSAGES kulccsal megfelelő szintre állítjuk a naplózást. Ha elindítjuk az egyik Tomcatet, valami ilyesmit kell látnunk a catalina.log-ban:
2010.06.20. 21:41:58 org.apache.coyote.http11.Http11Protocol init
INFO: Initializing Coyote HTTP/1.1 on http-8081
2010.06.20. 21:41:58 org.apache.catalina.startup.Catalina load
INFO: Initialization processed in 944 ms
2010.06.20. 21:41:58 org.apache.catalina.core.StandardService start
INFO: Starting service Catalina
2010.06.20. 21:41:58 org.apache.catalina.core.StandardEngine start
INFO: Starting Servlet Engine: Apache Tomcat/6.0.26
2010.06.20. 21:41:58 org.apache.catalina.ha.tcp.SimpleTcpCluster start
INFO: Cluster is about to start
2010.06.20. 21:41:58 org.apache.catalina.tribes.transport.ReceiverBase bind
INFO: Receiver Server Socket bound to:/192.168.68.102:4001
2010.06.20. 21:41:58 org.apache.catalina.tribes.membership.McastServiceImpl setupSocket
INFO: Setting cluster mcast soTimeout to 500
2010.06.20. 21:41:58 org.apache.catalina.tribes.membership.McastServiceImpl setupSocket
INFO: Setting cluster mcast TTL to 1
2010.06.20. 21:41:58 org.apache.catalina.tribes.membership.McastServiceImpl waitForMembers
INFO: Sleeping for 1000 milliseconds to establish cluster membership, start level:4
2010.06.20. 21:41:59 org.apache.catalina.tribes.membership.McastServiceImpl waitForMembers
INFO: Done sleeping, membership established, start level:4
2010.06.20. 21:41:59 org.apache.catalina.tribes.membership.McastServiceImpl waitForMembers
INFO: Sleeping for 1000 milliseconds to establish cluster membership, start level:8
2010.06.20. 21:42:00 org.apache.catalina.tribes.membership.McastServiceImpl waitForMembers
INFO: Done sleeping, membership established, start level:8
2010.06.20. 21:42:00 org.apache.catalina.startup.HostConfig deployDirectory
INFO: Deploying web application directory examples
2010.06.20. 21:42:01 org.apache.catalina.ha.session.DeltaManager start
INFO: Register manager /examples to cluster element Engine with name Catalina
2010.06.20. 21:42:01 org.apache.catalina.ha.session.DeltaManager start
INFO: Starting clustering manager at /examples
2010.06.20. 21:42:01 org.apache.catalina.ha.session.DeltaManager getAllClusterSessions
INFO: Manager [localhost#/examples]: skipping state transfer. No members active in cluster group.
2010.06.20. 21:42:02 org.apache.coyote.http11.Http11Protocol start
INFO: Starting Coyote HTTP/1.1 on http-8081
2010.06.20. 21:42:02 org.apache.catalina.startup.Catalina start
INFO: Server startup in 3825 ms
Amennyiben beindítjuk a másik Tomcat példányt, az első logjában valami hasonló fog megjelenni.
2010.06.20. 21:43:51 org.apache.catalina.tribes.io.BufferPool getBufferPool
INFO: Created a buffer pool with max size:104857600 bytes of type:org.apache.catalina.tribes.io.BufferPool15Impl
2010.06.20. 21:43:52 org.apache.catalina.ha.tcp.SimpleTcpCluster memberAdded
INFO: Replication member added:org.apache.catalina.tribes.membership.MemberImpl[tcp://{192, 168, 68, 102}:4000,{192, 168, 68, 102},4000, alive=1016,id={48 -51 24 -48 -107 11 64 47 -94 -68 -110 -105 -15 21 -103 -51 }, payload={}, command={}, domain={}, ]
Ezután indítsuk el az Apache HTTP Servert, és próbáljuk meg a következő lépéseket.
- Elindult az első Tomcat. Mivel a web.xml-ben a distributed tag be van állítva, a Tomcat meghívja a SimpleTcpCluster-t, hogy a StandardManager helyett DeltaManager-t példányosítson, ami majd a replikációt végzi. Majd beindulnak a multicast és unicast szolgáltatások.
- Beindul a második Tomcat példány, és bekerül a csoportba, és a többi példánytól elkéri a session állapotokat. Amennyiben 60 mp után a már futó Tomcat példány nem válaszol, hibaüzenet kerül a logba.
- Indítsuk el az Apache-ot is.
- Kérjük le a példa oldalt (/examples/servlets/servlet/SessionExample), és tegyünk el a sessionbe egy értéket. Session jön létre, melyet a ReplicationValve a válasz visszaadása előtt átküld a többi példánynak.
-
Állítsuk le az első példányt, ekkor ez kikerül a csoportból, és a második példány logjában valami ilyesmit fogunk látni:
2010.06.20. 21:58:14 org.apache.catalina.tribes.group.interceptors.TcpFailureDetector memberDisappeared INFO: Verification complete. Member disappeared[org.apache.catalina.tribes.membership.MemberImpl[tcp://{192, 168, 68, 102}:4001,{192, 168, 68, 102},4001, alive=975391,id={-26 13 57 -111 103 111 70 81 -90 -112 -30 -61 39 -102 0 92 }, payload={}, command={66 65 66 89 45 65 76 69 88 ...(9)}, domain={}, ]] 2010.06.20. 21:58:14 org.apache.catalina.ha.tcp.SimpleTcpCluster memberDisappeared INFO: Received member disappeared:org.apache.catalina.tribes.membership.MemberImpl[tcp://{192, 168, 68, 102}:4001,{192, 168, 68, 102},4001, alive=975391,id={-26 13 57 -111 103 111 70 81 -90 -112 -30 -61 39 -102 0 92 }, payload={}, command={66 65 66 89 45 65 76 69 88 ...(9)}, domain={}, ] - Kérjük le újra az oldalt. A kérést a második példány fogja kiszolgálni, és a sessionben láthatjuk, hogy benne maradt a hozzáadott érték.
- Az első példány visszaindításával az bekerül újra a csoportba, és induláskor lekéri a második példánytól a session állapotokat. A kéréseket újra az első példány fogja kiszolgálni.
- Session invalidáció kérésekor, vagy timeout esetén egy invalidációs üzenet megy a másik példányra.
A Clusterhez tartoznak JMX MBean-ek is, melyhez a Tomcatet úgy kell indítani, hogy azok lekérdezhetőek legyenek. Ehhez a bin/setenv.bat állományba helyezzünk el a következő sorokat, és ezután akár JConsole-lal, akár JMX Ant taskokkal csatlakozni tudunk. Vigyázzunk, hogy a két példánynál különböző portokat adjunk meg, ha egy gépen futnak.
set CATALINA_OPTS=\
-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=9012 \
-Dcom.sun.management.jmxremote.ssl=false \
-Dcom.sun.management.jmxremote.authenticate=false
Hibakeresésben segíthet a netstat parancs, mely a nyitott portokat, hálózati kapcsolatokat képes kilistázni. Amiket mindenképpen látnunk kell, a posztban konfigurált szoftver komponensek esetén (összes TCP kapcsolat, az utolsó kivételével, mely UDP):
- 8005: Tomcat 1. példány server port
- 9005: Tomcat 2. példány server port
- 8081: Tomcat 1. példány HTTP Connector
- 9081: Tomcat 2. példány HTTP Connector
- 8080: Apache HTTP Server
- 4000: Tomcat 1. példány cluster unicast port
- 4001: Tomcat 2. példány cluster unicast port
- 9012: Tomcat 1. példány JMX port
- 9013: Tomcat 1. példány JMX port
- 45564: multicast port, melyen mindkét Tomcat hallgat
A fürtözéssel kapcsolatban ne felejtsük el a következőket. A web alkalmazásunk áteresztőképessége ugyan nőhet (kiszolgált kérések/idő), de egy kérés kiszolgálási ideje is nőni fog, a bonyolultabb architektúra miatt. Emiatt a fürtözés nem alkalmas performancia problémák megoldására. Ebben az esetben javasolt az alkalmazás valamilyen profile eszközzel való megvizsgálása, és optimalizálása, vagy valamilyen cache alkalmazása.
Meg kell még említeni azt is, hogy horizontális skálázás esetén különböző funkciókat különböző hardver elemeken futtatunk. A webes technológiák, a Tomcat nem nyújt erre beépített lehetőséget. Az EJB használata esetén azonban lehetséges, hogy kizárólag konfigurációval bizonyos beaneket más virtuális gépben futó alkalmazásszerverekre helyezzünk át. Ez a lokális transzparencia. Ekkor az átviteli protokoll az RMI lesz. A Spring is lehetőséget biztosít erre, itt viszont választhatunk különböző protokollok között, mint RMI, Hessian/Burlap, HTTPInvoker, JMS, SOAP, stb.