Entitások auditálása Hibernate Envers-szel
Frissítve: 2014. január 4.
Felhasznált technológiák: Hibernate 4.3.0, HSQLDB 2.3.1, SLF4J 1.7.5, JUnit 4.11, Apache Commons DbUtils 1.5, Maven 3.0.3
A Hibernate Envers egy nagyon egyszerű Hibernate modul arra, hogy az entitásokat auditáljuk, azaz módosításkor a régi értékek is megmaradjanak az adatbázisban, és azokat bármikor előkereshessük.
Gyakori megrendelői igény, hogy látni lehessen, hogy ki, mikor és mit módosított bizonyos entitásokon, rekordokon. Az alkalmazásfejlesztő szeretné ezt minél transzparensebb módon kezelni, szóval lehetőleg ne kelljen ehhez a kódot módosítani. Egyszerű megoldás, hogy az aktuális és az audit rekordok is ugyanabban a táblában maradnak, és egy flag-et állítunk. Ezt meg lehet oldani alacsonyabb szinten is, pl. adatbázis triggerek alkalmazásával. Azaz a táblára kell tenni egy pre-insert, pre-delete és pre-update triggert, mely az adott rekordokat átmásolja egy másik, szerkezetileg hasonló táblába. Persze ehhez a triggert nekünk kell megírnunk. Az Oracle az audit rekordokat tartalmazó táblát Journal Table-nek nevezi, és bizonyos eszközök, pl. az Oracle Designer/2000, képesek ezeket, és a hozzá tartozó triggereket automatikusan legenerálni. Ha nem adatbázis alapú megoldást szeretnénk alkalmazni, használhatjuk pl. JPA esetén annak életciklus metódusait. Ennél azonban magasabb szintű, és szabványosabb megoldást biztosít a Hibernate Envers.
Az Envers gyakorlatilag beépül a Hibernate-be, és akár natív módon, akár JPA-n keresztül használjuk, kihasználhatjuk az előnyeit. Működik különálló alkalmazásban, de alkalmazásszerveren belül is, ahol a Hibernate végzi a perzisztenciát. A Subversion-höz hasonlóan az Envers is bevezeti a revision fogalmát. Gyakorlatilag minden tranzakció, mely auditálandó entitást szúr be, módosít vagy töröl, kap egy revision számot, mely a rendszeren belül egyedi. Minden revision-höz elmenti annak dátumát is. Minden entitáshoz létrehoz egy audit táblát is, melybe módosításkor vagy törléskor elmenti az előző állapotot, és természetesen hozzácsapja ezt a revision számot is. Utána a standard lekérdezésekkel elérjük a normál entitásainkat, de lehetőségünk van akár revision szám, akár dátum alapján visszakeresnünk az entitásaink régebbi állapotait.
Használata rendkívül egyszerű, jól
dokumentált
mutatja be a lehetőségeit. Én is készítettem egy egyszerű Maven-es
projektet, mely letölthető a
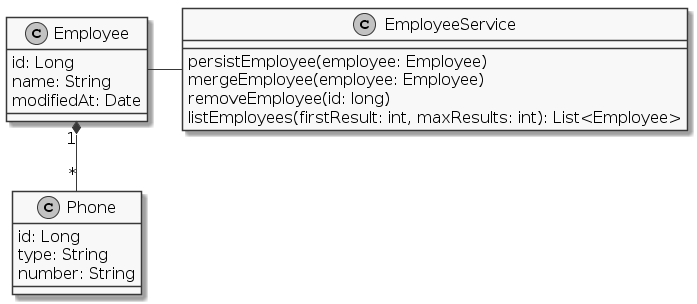
GitHubról. Ez a
tipikus Employee, Phone entitásokból áll, valamint az ezen CRUD
műveleteket végző EmployeeService osztályból, mely JPA-t használ. Az
EmployeeServiceTest teszt eset mutatja az Envers képességeit. A teszt
esetek az mvn test parancs kiadásával futtathatóak. Adatbázis telepítése
nem szükséges, memóriában futó HSQLDB-t használ.
[
Az Envers használatához szükséges, hogy a classpath-ban legyen, ehhez a Mavenben a következő függőséget kell felvennünk:
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-envers</artifactId>
<version>${hibernate.version}</version>
</dependency>Előző verziókban még konfigurálunk kellett a persistence.xml-ben a
listenereket, most már elég, ha a jar a classpath-on van.
Ahhoz, hogy egy entitást az Envers auditáljon, el kell helyezni rajta az
@Audited annotációt. Amennyiben nem akarjuk az összes mezőjét auditálni,
elhelyezhetjük az annotációt a mezőkön is. A példában az Employee és a
Phone entitáson is elhelyeztük az annotációt.
@Entity
@Audited
public class Employee implements Serializable {
...
}Az Envers használatához semmi több nem szükséges, a standard JPA
műveleteket használva automatikusan megtörténik az auditálás. Ez annyit
jelent, hogy sémageneráláskor az Employee és Phone tábla mellé létrehoz
egy Employee_AUD és egy Phone_AUD táblát is, mely megegyezik az
eredeti táblákkal, azzal a különbséggel, hogy kiegészíti egy REV és egy
REVTYPE mezővel, valamint létrehoz egy REVINFO táblát, REV és REVTSTMP
mezővel. Minden egyes beszúráskor, módosításkor, vagy törléskor, mely
auditálandó entitást érint, létrehoz egy új revisiont, azaz beszúr egy
új rekordot a REVINFO táblába. Ad neki egy egyedi azonosítót, mely egy
automatikusan növekvő szám (REV mező), és a REVTSTMP mezőben letárolja
az aktuális dátumot, időt. Az entitás előző értékét az _AUD végű
táblába szúrja be, melynek REV mezője tartalmazza a revision egyedi
azonosítóját, valamint azt, hogy milyen művelet történt (0: ADD -
beszúrás, 1: MOD - módosítás, 2: DEL - törlés).
Természetesen lehetőség van az auditált entitások lekérdezésére is. Erre
a teszteset testForRevisionsOfEntity és testForEntitiesAtRevision
metódusai mutatnak példákat. A legegyszerűbb lekérdezni egy revisionhöz
tartozó entitást:
AuditReader auditReader = AuditReaderFactory.get(em);
Employee revision = (Employee) auditReader.createQuery()
.forEntitiesAtRevision(Employee.class, 1).getSingleResult();Látható, hogy az audit entitások kezelésére az AuditReader való. Ennek
is vannak hasznos metódusai, mint a findRevision, getCurrentRevision,
getRevisionDate, getRevisionNumberForDate, getRevisions, stb. De ezeknél
sokkal rugalmasabb a Criteria API-hoz hasonlatos lekérdezési lehetőség a
createQuery metódus használatával. Itt fluent interfész használatával
további feltételeket tudunk megadni. Pl. nézzük meg az összes revision
lekérdezését az Employee osztályhoz:
List revisions = auditReader.createQuery()
.forRevisionsOfEntity(Employee.class, false, true).getResultList();Ez egy List<Object> példánnyal fog visszatérni. A lista elemei
tartalmazzák a revisionöket. Egy elem három objektumot tartalmaz. Az
első az audit entitás, a második egy DefaultRevisionEntity példány, mely
tartalmazza a revision azonosítóját és dátumát, a harmadik a
RevisionType enum egy értéke (ADD, MOD, DEL). Persze az
AuditQueryCreator metódusaival ezt a lekérdezést tovább finomíthatjuk,
hogy csak a számunkra fontos értékeket adja vissza.
Az Enverst természetesen tovább tudjuk konfigurálni, pl. globális
paraméterek használatával, vagy további annotációkkal. Pl. megadhatjuk a
táblák prefixét, suffixét, mezők neveit, sémát, katalógust. Az
@AuditTable, @SecondaryAuditTable(s) annotációkkal entitásonként
adhatjuk meg az audit tábla nevét. @AuditOverride(s) annotációval a
mezők neveit tudjuk felülírni. Amennyiben egy kapcsolatban a cél
entitást nem akarjuk auditálni, használjuk a @Audited(targetAuditMode =
RelationTargetAuditMode.NOT_AUDITED) annotációt. Ekkor a betöltött
audit entitás mindig az aktuális cél entitásra fog mutatni.
Megtehetjük azt is, hogy minden revision-höz saját adatokat mentünk el.
Pl. a módosítást végző felhasználó nevét. Ekkor vagy a
DefaultRevisionEntity osztályt kell kiterjeszteni, vagy a
@RevisionNumber és @RevisionTimestamp annotációkat használni, és
felvenni a megfelelő attribútumokat. Mindkét esetben az osztályt el kell
látni a @RevisionEntity annotációval, és meg kell adni egy
RevisionListener interfészt megvalósító osztályt, mely newRevision
metódusát hívja meg az Envers. Ebben lehet beállítani az előbb említett
példa esetén a bejelentkezett felhasználó nevét.
Itt érdemes megemlékezni a Commons
DbUtils projektről is. A teszt
esetben ugyanis az audit táblák tartalmát JDBC-n keresztül akartam
ellenőrizni. A JDBC túl nehézkes, Connection, Statement, ResultSet
építésével és a kivételkezelésével. Nem akartam emiatt bevetni a
Springet (ágyúval verébre), hogy a JdbcTemplate-et használhassam, így
Commons DbUtilsra esett a választásom, mellyel egyszerűen lehet
adatbázis műveleteket futtatni. Nézzünk is néhány példát, melyek
magukért beszélnek:
QueryRunner runner = new QueryRunner();
runner.update(conn, "delete from Employee");
Map result = runner.query(conn,
"select count(*) as cnt from revinfo", new MapHandler());
assertEquals(1, result.get("cnt"));
List<Map><String, Object[]> results = runner.query(conn,
"select * from Employee_AUD order by rev", new MapListHandler());
assertEquals(1, results.size());
assertEquals("name1", results.get(0).get("name"));