MDC naplózáskor és distributed tracing
A naplózó keretrendszerekben (legalábbis a Log4J-ben és a Logbackben) elég régóta ott a Mapped Diagnostic Context, ami egy nagyon hasznos eszköz, mégis aránylag ritkán látom használni.
Egy terhelés alatt lévő webes alkalmazásnál a naplóbejegyzéseket alapvetően elég nehéz szétválogatni pl. kérésenként, sessionönként/felhasználónként. Az MDC segítségével minden napló bejegyzésbe elhelyezhetük olyan adatot (pl. session azonosítót, felhasználónevet), mely ezek azonosítását teszi lehetővé. Ráadásul tehetjük ezt anélkül, hogy a naplózás helyén a hívást, és benne az üzenetet módosítanunk kéne.
A naplóüzenetek címkézése, azonosítása különösen fontos lehet elosztott, microservice környezetben, ahol különböző gépekről beérkező naplóüzeneteket kell összekötnünk.
A megvalósítás egyszerű, az MDC-t úgy képzeljük el, mint egy mapet, ami az adott szálhoz van
kötve. Ebbe a mapben helyezhetünk el értékeket, melyek egész addig ott lesznek, míg a szál
el nem végezte a feladatát. Utána egyszerűen konfigurálhatjuk, hogy ezek az értékek jelenjenek meg
minden naplóüzenetben. A szálhoz kötés egy ThreadLocal példánnyal történik.
Egyszerű alkalmazásban
Mivel az MDC a Log4J-ben és a Logbackben is elérhető, az SLF4J is tartalmazza. Mivel különösen webes alkalmazásnál hasznos, én egy Spring Bootos alkalmazással fogom bemutatni, amiben Logback az alapértelmezett naplózó implementáció. Ettől függetlenül mindenütt használható, ahol naplózás van.
A példa projekt elérhető a GitHubon.
Az MDC-be értéket betenni a következőképp lehet:
MDC.put("username", "johndoe");
Utána már csak az application.properties fájlban (, vagy ha több mindent szeretnénk megadni, akkor
a Logback konfigurációs XML fájljában) kell konfigurálni a layoutot:
logging.pattern.console = %d{HH:mm:ss.SSS} [%thread] [%X{username}] %-5level %logger{36} - %msg%n
Látható, hogy a %X{username} részlet írja ki a bejelentkezett felhasználót minden napló bejegyzés
esetén. Azaz legyen a hívás a következő.
log.info("Hello Spring Boot");
A hozzá tartozó naplóbejegyzés:
16:33:38.349 [http-nio-8080-exec-1] [johndoe] INFO hello.HelloController - Hello Spring Boot
Figyeljük meg a példában, hogy egy Spring MVC controllerből naplózunk, és a log attribútumot
a Lombok @Slf4j annotáció hozza létre.
@RestController
@Slf4j
public class HelloController {
@GetMapping("hello")
public String sayHello() {
log.info("Hello Spring Boot");
return "Hello Spring Boot";
}
}
Ez jó, ha van felhasználónk, de mi van akkor, ha a különböző http kérésekhez tartozó napló üzeneteket szeretnénk megkülönböztetni? Ekkor érdemes minden kéréshez gyártani egy egyedi azonosítót, legyen ez a tracking id, és egy Servlet Filterrel tegyük ezt meg, minden bejövő http kérésnél.
@Component
public class TraceFilter extends OncePerRequestFilter {
public static final String TRACE_ID_MDC_KEY = "traceId";
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
var traceId = UUID.randomUUID().toString();
MDC.put(TRACE_ID_MDC_KEY, traceId);
try {
filterChain.doFilter(request, response);
} finally {
MDC.remove(TRACE_ID_MDC_KEY);
}
}
}
Figyeljük meg, hogy a Springben lévő OncePerRequestFilter az ősosztály, ami kérésenként egyszer fut csak le.
(Ezt egy request attribute-tal oldja meg.)
Ennek megfelelően a módosított pattern a következő.
logging.pattern.console = %d{HH:mm:ss.SSS} [%thread] [%X{traceId}] %-5level %logger{36} - %msg%n
És a kiírt napló üzenet egy generált UUID-t tartalmaz.
16:33:38.349 [http-nio-8080-exec-1] [84cb2c52-c021-41e0-bddb-a9c53472a550] INFO hello.HelloController - Hello Spring Boot
Észrevehetjük, hogy a REST webszolgáltatások tesztelésére használt Postman is küld egy
egyedi azonosítót kérésenként Postman-Token http headerben. Ez jól használható
teszteléskor, hogy meg tudjuk feleltetni a naplóüzeneteket a kéréseinknek. (Amúgy
az említett header azért került bele, mert a Chrome-ban volt egy bug, a http kérések kezelésében.
Ha elküldött egy http kérést, és ha közben ugyanazokkal a paraméterekkel elküldött egy másikat is,
akkor ha az első visszatért, akkor annak válaszát adta vissza a második válaszaként is. Ha viszont
akár csak a headerben is különböztek, már a második választ adta vissza a második hívás válaszaként.)
Módosítsuk a filtert, hogy vegye ki ezt a headert, tegye át az MDC-be, és írja ki a naplóba.
@Component
public class TraceFilter extends OncePerRequestFilter {
public static final String TRACE_ID_MDC_KEY = "traceId";
public static final String POSTMAN_TOKEN_MDC_KEY = "postmanToken";
public static final String POSTMAN_TOKEN_HEADER_NAME = "Postman-Token";
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
var traceId = UUID.randomUUID().toString();
var postmanToken = request.getHeader(POSTMAN_TOKEN_HEADER_NAME);
var userAgent = request.getHeader(USER_AGENT_HEADER_NAME);
MDC.put(TRACE_ID_MDC_KEY, traceId);
MDC.put(POSTMAN_TOKEN_MDC_KEY, postmanToken);
try {
filterChain.doFilter(request, response);
} finally {
MDC.remove(TRACE_ID_MDC_KEY);
MDC.remove(POSTMAN_TOKEN_MDC_KEY);
}
}
}
A módosított pattern a következő.
logging.pattern.console = %d{HH:mm:ss.SSS} [%thread] [%X{traceId},%X{postmanToken}] %-5level %logger{36} - %msg%n
És a kiírt napló üzenet.
16:33:38.349 [http-nio-8080-exec-1] [84cb2c52-c021-41e0-bddb-a9c53472a550,1e8653f5-83f6-4bb0-9d45-004af1867763] INFO hello.HelloController - Hello Spring Boot
Ahol az első UUID a szerver által kiosztott trace id, a második pedig a Postman által küldött Postman Token.
A Logback érdekes tulajdonsága, hogy különböző filtereket lehet definiálni, ezzel szűrni a naplóüzeneteket.
Módosítsuk a filterünket, hogy ne csak a Postman-Token értekét vegye ki a headerből, hanem a User-Agent
értékét is, majd szintén tegye át az MDC-be.
Ezután pl. ez alapján a MDCFilter-rel tudunk szűrni. Ehhez viszont már nem elegendő az application.properties
állomány, hanem saját xml konfigurációt kell alkalmazni. Viszont ezt meg kell adni az application.properties
fájlban.
logging.config = classpath:hello-logback.xml
És a hello-logback.xml tartalma a következő.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="CONSOLE_LOG_PATTERN" value="%d{HH:mm:ss.SSS} [%thread] [%X{traceId},%X{postmanToken}] %-5level %logger{36} - %msg%n"/>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml"/>
<turboFilter class="ch.qos.logback.classic.turbo.MDCFilter">
<MDCKey>userAgent</MDCKey>
<Value>PostmanRuntime/7.28.4</Value>
<OnMatch>DENY</OnMatch>
</turboFilter>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
</configuration>
Itt is látható egy kis Logback + Spring Bootos trükk, hogy include-áljuk a default
konfigot a defaults.xml és console-appender.xml állományokból.
(Valamint nagyon fontos megjegyzés, hogy ezekben az xml állományokban akár
environment property-ket is alkalmazhatunk, ami különösen hasznos lehet, ha az
alkalmazásunkat pl. Docker konténerben futtatjuk. Ekkor a ${USERAGENT_PREFIX}
formátumot használhatjuk.)
Az MDCFilter csak pontos egyezőséget képes vizsgálni. Saját filter implementálása
gyerekjáték.
public class UserAgentMdcFilter extends TurboFilter {
private String prefix;
@Override
public FilterReply decide(Marker marker, Logger logger, Level level, String format, Object[] params, Throwable t) {
var userAgent = MDC.get(TraceFilter.USER_AGENT_MDC_KEY);
if (userAgent != null && userAgent.toLowerCase().startsWith(prefix.toLowerCase())) {
return FilterReply.DENY;
}
return FilterReply.NEUTRAL;
}
public void setPrefix(String prefix) {
this.prefix = prefix;
}
}
A DENY azt jelenti, hogy a naplóbeüzenetet ki kell szűrni. További értékei a NEUTRAL, amikor
további filterek dönthetnek, vagy a ACCEPT, amikor a naplóüzenet azonnal kiírható.
Az ehhez tartozó xml konfiguráció olvasható alább.
<turboFilter class="hello.UserAgentMdcFilter">
<prefix>PostmanRuntime</prefix>
</turboFilter>
Látható, hogy milyen elegáns a konfiguráció is, hiszen csak egy settert kellett definiálni.
Microservice környezetben
Microservice környezetben kihívást okozhat a különböző microservice-ek által
beküldött naplóüzenetek összepárosítása. Képzeljük el, hogy az A
microservice hívja a B-t, és az a C-t, és szeretnénk a kéréshez
tartozó, de az összes rendszerben keletkezett naplóüzeneteket egyben
látni.
Erre való a Distributed tracing
minta. Az alapötlet ugyanaz. A kéréshez társítsunk egy azonosítót (elnevezési konvenció szerint tracing id),
valamint minden rendszerben végrehajtott egy vagy több művelet kapjon szintén egy egyedi azonosítót (elnevezési
konvenció szerint span id). Ezek a spanek hierarchiába rendezhetők, hiszen az A rendszerben
a kérés kapott egy A-1 span id-t, ez továbbhívott a B rendszerbe, átadva ez az id-t, és
az ott végrehajtott művelet kapot egy B-1 id-t. A B-1 spannek az A-1 a szülője.
Más nevezéktanban correlation id-ként hivatkoznak a rendszereken átívelő azonosítóra.
Ahhoz, hogy ez működjön, ezeket az azonosítókat az első hívás helyén ki kell osztani, ki kell naplózni (ehhez nagyon jól jön a fent említett MDC), és tovább kell adni, és a továbbadottat ki is kell olvasni. Ezek programozása nem nagy kihívás, talán a továbbadás lehet érdekesebb. Ez REST hívás esetén lehet http headerben, aszinkron üzenetek küldése esetén lehet az üzenet fejlécében.
Azonban, hogy ne kelljen ezt nekünk magunk implementálni, Spring Boot alkalmazásban használhatjuk a
Spring Cloud Sleuth
projektet. Ez létrehoz egy beant, melyet lehet aztán injektálni, és programozottan
elindíthatunk és leállíthatunk egy spant, és természetesen elvégzi az azonosítók
generálását is (még API is van rá, ez az OpenTracing API). Valamint ezeket az azonosítókat a naplóüzenetekben is elhelyezi (MDC használatával).
Alkalmazhatunk deklaratív konfigurációt is annotációk használatával.
De a legnagyobb ereje talán abban van, hogy különböző eszközökhöz implementálva van
ezen azonosítók továbbadása, azaz a propagáció. Erre több mechanizmus is van,
pl. AWS, B3, W3C. A B3 pl. a specifikáció alapján
nagyon egyszerű:
X-B3-TraceId: 80f198ee56343ba864fe8b2a57d3eff7
X-B3-ParentSpanId: 05e3ac9a4f6e3b90
X-B3-SpanId: e457b5a2e4d86bd1
X-B3-Sampled: 1
Ha ezt http headerben, vagy üzenet headerben szeretnénk továbbadni, nem kell magunknak megoldanunk, mert a Spring Cloud Sleuth tartalmaz integrációt a következő eszközökhöz: Rest Template, WebClient, RabbitMQ, Kafka, JMS, OpenFeign, stb.
Ezzel már megtörténik az id generálás, propagáció, a propagált beolvasása is, a naplózás.
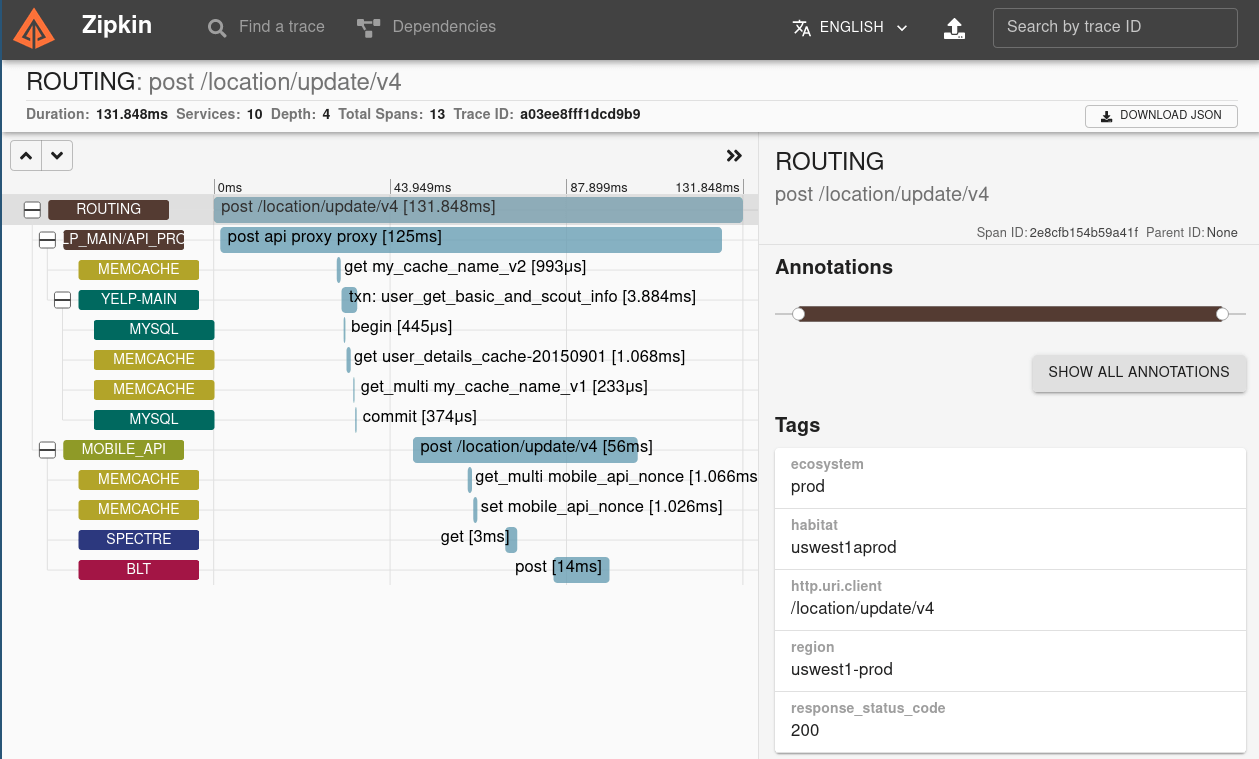
Már csak meg kéne jeleníteni. Erre való Zipkin, aminek http-n,
Kafkán, vagy bármilyen soron keresztül is képes továbbítani az adatokat.
A Zipkin grafikusan tudja megjeleníteni a trace-hez tartozó spaneket, az idő függvényében.