JPA több one-to-many kapcsolat
Felhasznált technológiák: Spring Boot 3.2, Spring Data JPA
Frissítve: 2024. március 1.
Már írtam egy posztot a JPA teljesítményhangolásával, valamint a lazy loadinggal kapcsolatban. Ott egy entitáshoz egy másik kapcsolódott, one-to-many kapcsolattal. Ott folytatom, ahol abbahagytam, de most egy entitáshoz két másik entitás kapcsolódik ugyanazon, one-to-many kapcsolattal. Egyrészt megvizsgálom a Hibernate egy jellegzetes hibaüzenetét, valamint elemzek több megoldást is performancia szempontból.
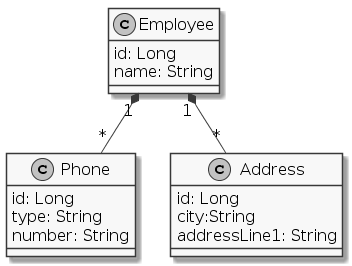
Az adatmodell a következő osztálydiagramon látható. Egy Employee
példányhoz több Phone és több Address példány kapcsolódik.
A posthoz tartozó példaprogram letölthető a
GitHub-ról. A
projekt letöltése után az mvnw test paranccsal futtathatóak a teszt esetek.
A projekt ebben a
posztban bemutatott legutolsó megoldást tartalmazza, de megjegyzésben
ott van a többi megoldás is.
Elkészítjük a három entitást a kötelező annotációkkal, valamint a lekérdező metódust.
@Transactional(readOnly = true)
public Employee findEmployeeById(long id) {
return employeeRepository.findById(id).orElseThrow();
}
Teszt esetből meghívva a következő
kivételt kapjuk:
org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: employees.Employee.addresses: could not initialize proxy - no Session.
Az előző posztból tudhatjuk, hogy ez azért van, mert a @OneToMany
annotáció használatakor a kapcsolódó entitásokat csak akkor tölti be,
mikor szükség van rá (default a lazy loading). De mivel a teszt eset
kéri le először a kapcsolódó entitásokat, a persistence context már
zárva, a session zárva, így a Hibernate ezeket már nem tudja lekérdezni.
Első megoldás, mely eszünkbe juthat, hogy egészítsük ki a @OneToMany
annotációkat a fetch = FetchType.EAGER paraméterrel.
Ekkor a persistence provider két select utasítást ad ki.
select ... from employee e1_0 left join address a1_0 on e1_0.id=a1_0.employee_id where e1_0.id=?
select ... from phone p1_0 where p1_0.employee_id=?
Azonban ha azt a
metódust nézzük, mely az összes Employee példányt visszaadja
(findEmployees()), azonnal láthatjuk a különbséget, ugyanis öt SQL
utasítás futtat le.
Ez az ún. N+1 probléma, azaz lefut egy select az employee táblára,
valamint rekordonként egy select a phone és egy select az address táblára.
Ez a megoldás nem feltétlenül jó, mert ilyenkor mindig eager jönnek le a kapcsolódó entitások, nem tudok választani, hogy egyszer le akarom kérdezni azokat, egyszer nem. Finomabban szabályozható, ha a lekérdezésben adom meg, hogy mit akarok betölteni. Erre a join fetch való. Írjuk is át a lekérdezést, hogy a következő lekérdezést használja:
select distinct e from Employee e
join fetch e.phones
join fetch e.addresses where e.id = :id
Ekkor a következő kivételt kapjuk:
Caused by: java.lang.IllegalArgumentException: org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags: [employees.Employee.addresses, employees.Employee.phones]
Ekkor átállhatunk Set-re,
ekkor egy joint tartalmazó select utasítást
kapunk. Mi ezzel a probléma?
select distinct ... from employee e1_0
join phone p1_0 on e1_0.id=p1_0.employee_id
join address a1_0 on e1_0.id=a1_0.employee_id
where e1_0.id=?
Igen, jól látható, hogy a fenti select utasítás eredménye egy
Descartes-szorzat. Azaz ha a phone táblában van tíz rekord, és a address
táblában is van tíz rekord egy adott employee rekordhoz, a lekérdezés
száz rekordot fog visszaadni.
Mi lehet erre a megoldás? Tudjuk azt, hogy amíg él a persistence
context, addig a JPA provider a memóriában tárolja, hogy mik lettek
betöltve, és azokat nem kéri be újra. Tehát egyrészt lekérdezzük az
Employee entitást joinnal összekötve a Phone entitásokkal, majd egy
külön lekérdezésben az Employee entitást joinnal összekötve az Address
entitásokkal. Ez a következőkben látszik.
@Query("select distinct e from Employee e left join fetch e.phones where e.id = :id")
Employee findEmployeeByIdFetchPhones(long id);
@Query("select distinct e from Employee e left join fetch e.addresses where e.id = :id")
Employee findEmployeeByIdFetchAddresses(long id);
employeeRepository.findEmployeeByIdFetchPhones(id);
return employeeRepository.findEmployeeByIdFetchAddresses(id);
Megfigyelhetjük, hogy az első lekérdezés eredményével nem csinálunk
semmit. Csupán csak arra való, hogy az Employee és a Phone entitásokat a
persistence contextbe töltse. A második query igaz, hogy csak a Address
entitásokat kéri le, de mivel a Phone entitások már a persistence
contextben vannak, hozzáköti őket. Ehhez persze kell a @Transactional
annotáció (readOnly = true paraméterrel a sebesség érdekében, ekkor ugyanis
nem történik dirty check, azaz nem vizsgálja, hogy változott-e az entitás),
különben mindkét lekérdezéshez külön persistence contextet nyitna, így
ugyanúgy LazyInitializationException lenne a jutalmunk. A lefuttatott
két select utasítás a következő.
select distinct ... from employee e1_0 left join phone p1_0 on e1_0.id=p1_0.employee_id where e1_0.id=?
select distinct ... from employee e1_0 left join address a1_0 on e1_0.id=a1_0.employee_id where e1_0.id=?
Látható, hogy két select fut le, és nincs Descartes-szorzat.